Object Detection for Preventing Road Crashes and Saving Lives
10 min readUpdated October 16, 2025
Omdena
A team of 31 Omdena collaborators leveraged various AI techniques like object detection to help assess road crash risk at scale. The team applied labeling, object detection, CNNs, and various regression techniques to provide features for road safety estimation on roads globally.
Road Crashes: A Global Tragedy
More than 100,000 people are injured in road crashes every day, resulting in costs of over $6 billion every single day. Currently, road accidents represent the eighth leading cause of death globally and the leading cause of death for children and young adults aged 5–29 years. Moreover, it is estimated that 500 million people will suffer life-changing injuries or be killed in road crashes between now and 2030, with the economic cost being more than $25 trillion.
Various organizations and charities help the UN achieve road safety goals, reducing the devastating social and economic cost of road crashes. Among those is the International Road Assessment Programme (iRAP), which helps reduce road crashes globally through research and coding of road attributes, a 5-star road rating system built on those attributes, investment plans for road improvement guidance, and worldwide partnerships.
The AI challenge involved 31 collaborators, 35% of whom were women, from 17 different countries. Machine learning practitioners used their expertise on the project to address the serious impacts of road crashes and develop innovative solutions to address them.
Project goals
During the project, the team worked on the following challenges:
Identifying the most suitable existing crash data that could be used to train all the machine learning models developed by the team;
Detecting relevant road features from image and video data, possibly matching iRAP’s features;
Creating models to assess and predict road safety;
Assessing the importance of road features in predicting each type of star rating;
Producing a dashboard to help predict the 5-star rating using all the models developed during the project.
Real-world data science strategies and procedures were used throughout the project. The team went through the entire process from data collection, to preparation, and modeling. Finally, all the different workstreams have been summarised into a user-friendly dashboard to show the most relevant aspects and outputs of the work.
Assessing Road Risk To Save Lives
iRAP currently assesses road risk based on the value of more than 60 attributes that are coded for every 100-meter section of each road in the world. Features include traffic flow for cars, motorcycles, bicycles, pedestrians, and others; structural properties of the road, e.g., the number of carriageways and lanes, the types of intersections present, and the curvature of the road; the presence (or absence) of security features, e.g., shoulders and fencing; other road features, e.g., speed limits, lighting conditions, and many others.
Because attribute collection and coding are performed mainly manually, this process is a truly colossal effort given the large number of roads and attributes involved. For this reason, the main aim of the project was to make the whole process of feature extraction and road risk assessment faster and more efficient mainly through automation.
More specifically, we identified the following techniques that could help improve the current process:
Automatic road attribute extraction through computer vision techniques;
Road risk prediction based on historical vehicle accident data using regression and classification techniques;
Assess which specific road attributes are of the highest importance in evaluating the iRAP score;
Leveraging existing APIs with geospatial libraries to extract road attributes at scale.
The following image depicts the overall project workflow.
Overall project workflow. Source: Omdena
Applying Computer Vision
Computer vision techniques were used in this project to detect relevant road features from images at scale. Feature extraction from various sources was a crucial task for the project because the extracted features would provide the necessary training data for the machine learning models.
More specifically, volunteers worked on techniques to automatically extract road features from both ground-level imagery (e.g., Google street view) as well as from aerial level imagery (e.g., satellite photos). While ground-level imagery allows getting insights on numerous road features, aerial images allow to also recognize larger-scale features, e.g., road curvature and road intersection type, which would be difficult to estimate on the basis of ground-level images alone.
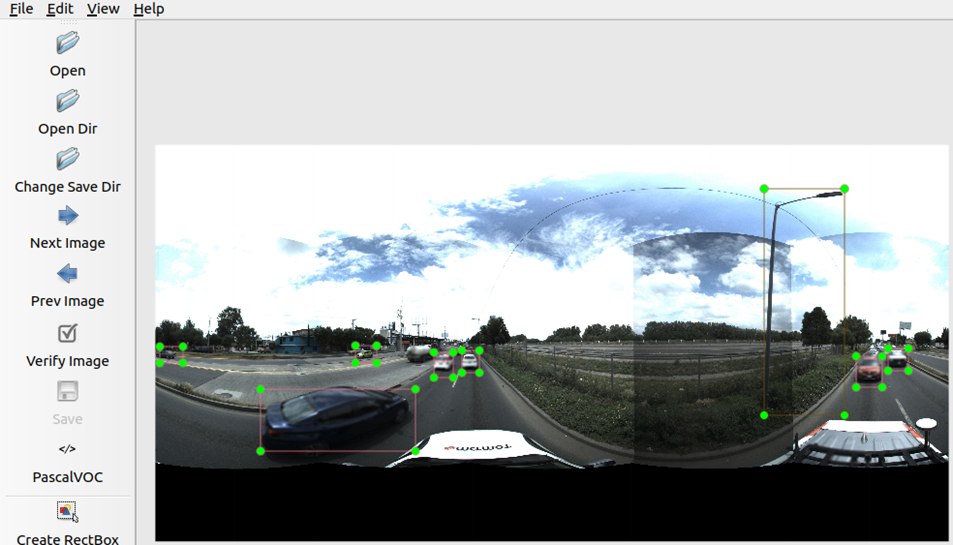
Labeling Panoramic Images
Feature detection in panoramic images proved to be particularly challenging due to the lack of numerous pre-trained models capable of detecting objects in panoramic images. Volunteers tackled this issue thanks to a sprint labeling exercise using a dataset provided by TomTom, and using the python labellmg package, a full tutorial on how that data was collected is here.
Using labelImg for annotating an image from the TomTom dataset. Source: TomTom and Omdena
Object Detection on Road Images
The most modern computer vision techniques have been implemented on various datasets, and their accuracy has been evaluated to determine the best performing model. Machine learning models that have been investigated for ground-level imagery include the You Look Only Once v3 (YOLOv3), the Histogram of Gradients (HOG), the MobileNet Single Shot Detector (SSD), and the RetinaNet. The YOLOv3 model was chosen in the end because it provided more flexibility for our requirements as well as a good enough performance.
Object detection applied to a still image recorded from Seattle traffic videos. Source: Omdena.
Feature Detection from Aerial Imagery
Concerning aerial level imagery, volunteers investigated various convolutional neural networks, including the VGG16, ResNet50, and Inceptionv3 models, to obtain traffic flow estimates. These models were trained on various datasets including the DOTA-v1.5 dataset. Road features were also obtained from OpenStreetMap data by means of the osmnx python package, and a model to detect the types of the intersection was developed using an autoencoder trained on Google Maps satellite images.
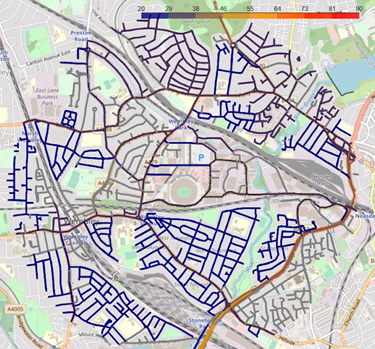
Maximum speed near Wembley Stadium, London, UK. Speed limit information retrieved from OpenStreetMaps. Source: Omdena
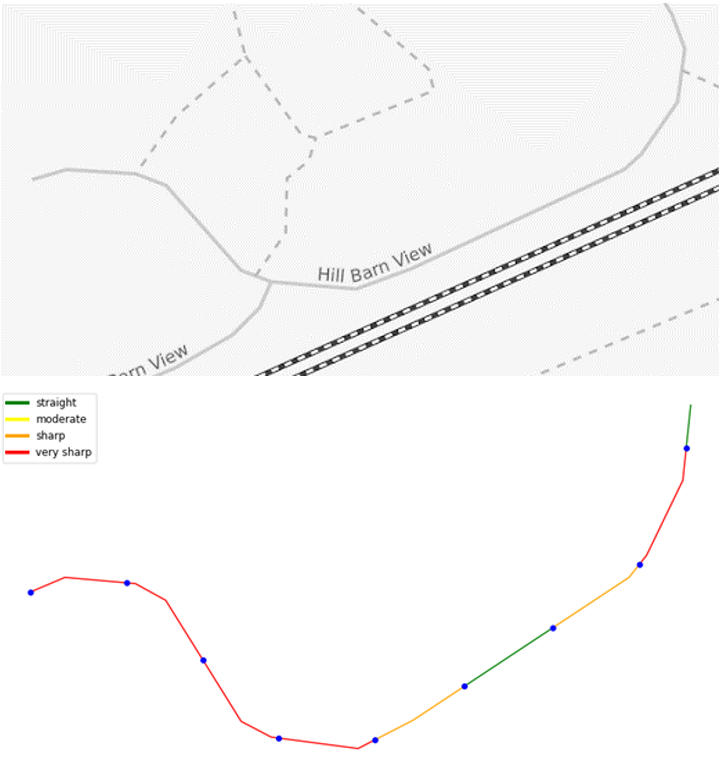
Work has also been done on detecting school road warning signs on roads by means of a ResNet50 model, and on detecting road curvature.
Road curvature estimation. Above is a map showing the original road and below is the estimation of its curvature for each 100m section. Source: Omdena
Regression Techniques
Regression techniques allow models to understand the relationship between one or multiple independent variables and a dependent variable. Regression techniques enable us to understand the strength of the relationship between the dependent variable and each independent variable, allowing as well to estimate what function best approximates such a relationship.
Road Feature Importance for iRAP Score
Regression models were considered in different workstreams in this project. First, regression models were used to assess what road features were of the highest importance in evaluating the iRAP score. In other words, the question that was being addressed was: what features, out of the 60+ available, can be used to approximate well enough the iRAP score of a road? To answer this question, volunteers worked on various types of regressors including random forest regressor, extreme gradient boosted (Xgboost) regressor, and categorical boost (catboost) regressor.
Road Risk Score Estimation
Regression techniques have also been used to compute the risk score automatically on the basis of historical road incident data. To this end, the comprehensive road safety dataset and the road traffic dataset, both published by the UK Department for Transport, were used as training datasets. The former dataset provides plenty of information on car accidents and road features, whereas the latter provides traffic information for various roads.
Additionally, OpenStreetMap’s data accessed through the Overpass API was used to calculate the distance between accidents and various landmarks, including schools, colleges, universities, hospitals, bars, pubs, and restaurants, which was one of the additional features that were used in our model. We trained both a random forest regressor and a gradient boosting regressor, using the level of accident severity as the target variable.
Importance of various road features, as estimated by a random forest regressor. Source: Omdena
One of iRAP’s priorities for this project involved scaling their data-driven operations with automation. Road attributes change over time and this, in turn, can change the rating a road receives. A pipeline using some of the above methods was developed to help create workflows that scale on a continuous basis. This pipeline demonstrated the capability to gather data, transform that data, train models, and predict iRAP road attribute scores.
Workflows were built using a python library called Prefect. Perfect allows the creation of directed acyclic graphs (DAG’s) which are labeled as “flows”. Flows are composed of “tasks” and logic around those tasks to help sequence them together towards a specific goal. A Perfect task can be created by decorating any python function or by leveraging an existing library of tasks built by others.
Example workflow depicting notebook-based “tasks” which gather road data, segment those roads, then determine the curvature rating of the segments. Source: Omdena
Flows created for this project involved tasks that ran Jupyter notebooks automatically with a library called Papermill. Papermill allows for automated and parameterized execution of notebooks. Using notebooks in this way allowed for straightforward transitions from analysis and experimentation to production-ready workflows. It also enables the flexibility for data scientists or engineers to expand or troubleshoot code in the future.
Reflections on the Project
A lot of data and great fun
The amount of data we could use was overwhelming, and, hence, rather difficult to process, e.g., be it because of the large number of pictures available to train our YOLOv3 model or because of the millions of records in the UK car accident datasets. Moreover, self-organizing workstreams focused on a large variety of machine learning techniques, allowing volunteers to experiment with many problems and types of approaches.
The power of collaboration!
After iRAP and Omdena provided the introduction to the problem at the beginning of the project, the collaborators quickly started to suggest the potential main development ideas, around which others started to gather. Discussions started to take place on our main collaboration channel (Slack) on whether to abandon or pursue some of them and later some tasks were chosen by the collaborators based on interest and on the relevance with the problem at hand.
Some collaborators opted to lead the various tasks and helped manage the workload among the collaborators and the different tasks. Regular weekly calls helped ensure the progress was on track and everyone was on the same page. Members from iRAP also helped guide the teams through iterative feedback and by answering questions.
A great journey for a great cause
We hope the worldwide collaboration and implementation of AI technologies on this project will help scale iRAP’s goals. The unique combination of Omdena’s model, global volunteer expertise, and iRAP’s data-driven approach created outcomes that may create safer roads for everyone. We had huge fun experimenting with so much data and so many different techniques, but, most importantly, we feel very proud to have had the opportunity to contribute to such an important cause.
All the volunteers who contributed to the project. Source: Omdena
References
Andreas Geiger, Philip Lenz, Christoph Stiller and Raquel Urtasun, Vision meets Robotics: The KITTI Dataset, International Journal of Robotics Research (IJRR), 2013
This article is written by Giulio Giaconi and Dave Bunten.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}