
Understanding Nature-Based Solutions through Natural Language Processing and Machine Learning
January 13, 2021

Nature-based solutions (NbS) can help societies and ecosystems adapt to drastic changes in the climate and mitigate the adverse impacts of such changes.
Why
NbS harness nature to tackle environmental challenges that affect human society, such as climate change, water insecurity, pollution, and declining food production. NbS can also help societies and ecosystems adapt to drastic changes in the climate and mitigate the adverse impacts of such changes through, for example, growing trees in rural areas to boost crop yields and lock water in the soil. Although many organizations have investigated the effectiveness of NbS, these solutions have not yet been analyzed to the full extent of their potential.
In order to analyze such NbS approaches in greater detail, World Resources Institute (WRI) partnered with Omdena to better understand how regional and global NbS, such as forest and landscape restoration, can be leveraged to address and reduce climate change impacts across the globe.
In an attempt to identify and analyze such approaches, we investigated three main platforms that bring organizations together to promote initiatives that restore forests, farms, and other landscapes and enhance tree cover to improve human well-being:
- The African Forest Landscape Restoration Initiative (AFR100): intending to place 100 million hectares of land across the African continent into restoration by 2030
- Initiative 20×20: goal to begin restoring or protecting 50 million hectares by 2030 across Latin America and the Caribbean
- Cities4Forests: partner with leading cities around the world to protect and restore forests
Considering the aforementioned, the project goal is to assess the network of these three coalition websites through a systematic approach and to identify climate adaptation measures covered by these platforms and their partners.
The integral parts of the project’s workflow included building a scalable data collection pipeline to scrape the data from the platforms and partnering organizations, and several useful PDFs; leveraging several techniques from Natural Language Processing, such as building a Neural Machine Translation pipeline to translate non-English text to English, performing sentiment analysis for identifying potential gaps, experimenting with language models that were optimal for the given use cases, exploring various supervised and unsupervised topic modeling techniques to get meaningful insights and latent topics present in the voluminous text data collected, leveraging the novel Zero Shot Classification(ZSC) to identify the impacts and interventions, building a Knowledge-Based Question Answering(KBQA) system, and recommender system.
Project workflow
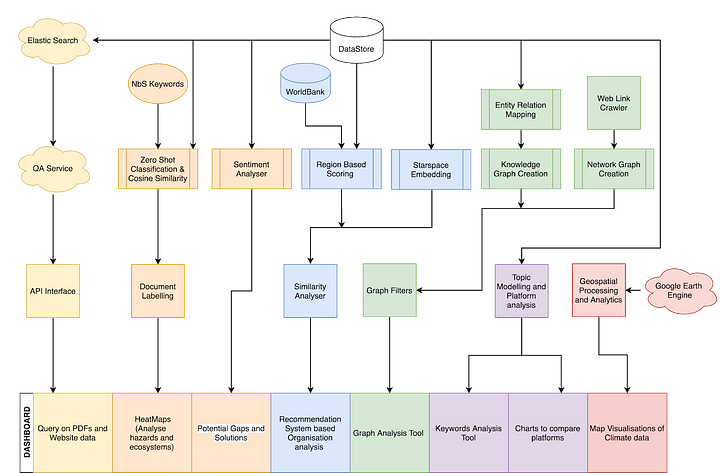
Data collection
The platforms engaged in climate-risk mitigation were studied for several factors, including the climate risks in each region, as well as initiatives taken by the platforms and their partners, NbS employed for mitigating climate risks, the effectiveness of adaptations, goals, road map of the platform, among others. This information was gathered through:
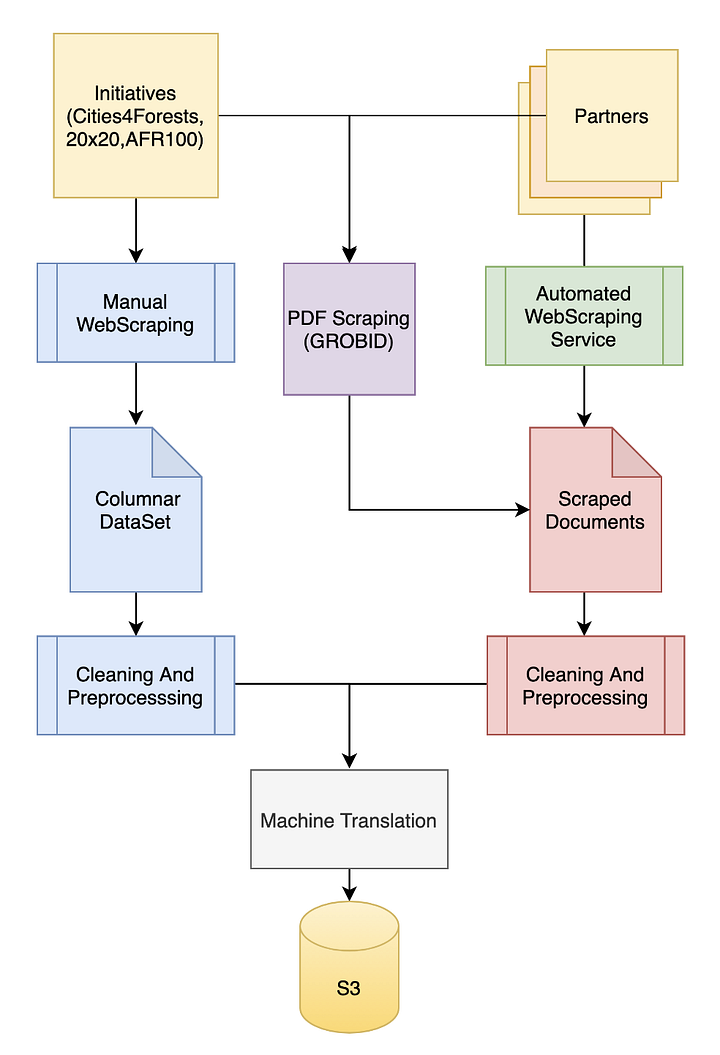
a) Heavy scraping of Platform websites: It involved data scraping from all the platforms´ website pages using Python scripts. This process involved manual effort in customizing the scraping suitable for each page; accordingly, extending this model would involve some effort. Approximately 10MB of data was generated through this technique.
b) Light Scraping of Platform websites and partner organizations: it involved the obtention of the platforms sitemap. Once it was done, organization websites were crawled to obtain the text information. This method can be extended to other platforms with minimal effort. The volume of this data generated is around 21MB.
c) PDF Text Data Scraping of Platform and Other Sites: The platform websites presented several informative PDF documents (including reports and case studies), which were helpful for use in the downstream models, including the Q&A system, recommendation system, etc. This process was completely automated by the PDF text-scraping pipeline, which prepares a CSV of the PDF data and then generates a consolidated CSV file containing paragraph text from all the PDFs mentioned in the input CSV file. This pipeline can be incrementally used to generate the PDF text in batches. The NLP models utilized all of the PDF documents from the three platform websites, as well as some documents containing general information on NbS referred by WRI. Approximately 4MB of data was generated from the available PDFs.
Data preprocessing
a) Data Cleaning: an initial step comprising the removal of unnecessary text, text with length <50, as well as duplicates.
b) Language Detection and Translation: This step involved the development of a pipeline for language detection and translation to be applied to text data gathered from the 3 main sources described above.
Language Detection was performed by analyzing text using different deep learning pre-trained models such as langdetect and pycld3. Once the language is detected, the result is used as an input parameter for the translation pipeline. In this step, pre-trained multilingual models are downloaded from the Helsinki NLP repository available at HuggingFace.com (an NLP processing company). Text is tokenized and organized in batches to be sequentially fed into the pre-trained model. To enhance function performance, the pipeline was developed with GPU support, if available. Also, once a model is downloaded. it is cached into the program memory so it doesn’t need to be downloaded again.
The translation performed well with the majority of texts to which it was applied (most were in Spanish or Portuguese), being able to generate well-structured and coherent results, especially considering the scientific vocabulary of the original texts.
c) NLP preparation: This step was applied to the CSVs files generated through the scrap, after translation pipeline and was composed by Punctuation removal, Stemming, Lemmatization, Stop words removal, Part of Speech tagging (POS), Tagging, Chunking
Data modeling
Statistical analysis
Statistical Analysis was performed on the preprocessed data by exploring the role of climate change impacts, interventions, and ecosystems involved in the three platforms’ portfolios using two different approaches: zero-shot classification and cosine similarity.
1.) Zero Shot Classification: This model assigns probabilities to which user-defined labels a text would best fit. We applied a zero-shot classification model from Hugging Face to classify descriptions for a given set of keywords belonging to climate-change impacts, interventions, and ecosystems for each of the three platforms. For ZSC, it combined the heavy-scraped datasets into one CSV for each website. The scores computed by ZSC can be interpreted as probabilities that the class belongs to a particular description. As a rule, we only considered as relevant those scores at or above 0.85.
Let’s consider the following example:
Description: The Greater Amman Municipality has developed a strategy called Green Amman to ban the destruction of forests The strategy focuses on the sustainable consumption of legally sourced wood products that come from sustainably managed forests The Municipality sponsors the development of sustainable forest management to provide long term social economic and environmental benefits Additional benefits include improving the environmental credentials of the municipality and consolidating the GAMs environmental leadership nationally as well as improving the quality of life and ecosystem services for future generations.
Model Predictions: The model assigned the following probabilities based upon the foregoing description:
- Climate Change Impact Predictions: ‘loss of vegetation’: 0.89 , ‘deforestation’: 0.35, ‘GHG emissions’: 0.23, ‘rapid growth’ : 0.20, ‘loss of biodiversity’: 0.15 … (21 additional labels)
- Types of Interventions Predictions: ‘management’: 0.92 , ‘protection’: 0.90 , ‘afforestation’: 0.65 , ‘enhance urban biodiversity’: 0.49, ‘Reforestation’: 0.38 … (16 additional labels)
- Ecosystems: ‘Temperate forests’: 0.66, ‘Mediterranean shrubs and Forests’: 0.62, ‘Created forest’: 0.57, ‘Tropical and subtropical forests’: 0.55 … (13 additional labels)
For the description above, we see that the Climate-Change-Impact prediction is ‘loss of vegetation’, Types-of- Intervention prediction is ‘management’ or ‘protection’, and the Ecosystems prediction is empty.
2.) Cosine Similarity: Cosine Similarity compares vectors created by keywords, generated through Hugging Face models…. (how these keywords were computed) and descriptions and scores the similarity in direction of these vectors. We then plot the scores with respect to technical and financial partners and a set of keywords. A higher similarity score means the organization is more associated with that hazard or ecosystem than other organizations. This approach was useful to validate the results of the ZSC approach.
Aligning these results, it was possible to answers the following questions:
- What are the climate hazards and climate impacts most frequently mentioned by the NbS platforms’ portfolios?
- What percentage of interventions/initiatives take place in highly climate-vulnerable countries or areas?
- What ecosystem/system features most prominently in the platforms when referencing climate impacts?
This model was applied on descriptions from all three heavy-scraped websites, and compared cross-referenced results (such as Climate Change Impact vs Intervention, or Climate Change Impact vs Ecosystems, or Ecosystems vs Intervention) for all three websites. Further, we created plots based on country and partners (technical and financial) for all three websites.
Sentiment analysis
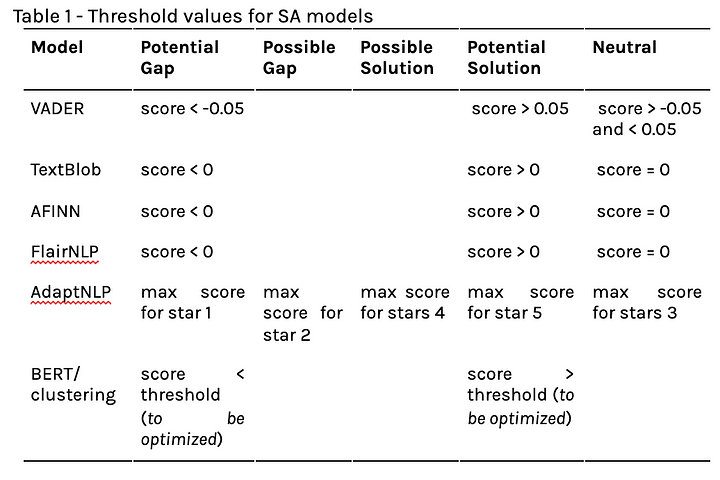
Sentiment Analysis (SA) is the automatic generation of sentiment from text, utilizing both data mining and NLP. Here, SA is applied to identify potential gaps and solutions through the corpus text extracted from the three main platforms. In this Task, it implemented the following well consolidated unsupervised approaches: VADER, TextBlob, AFINN, FlairNLP, AdaptNLP Easy Sequence Classification. A new approach, Bert-clustering, was proposed by Omdena Team and it is based on Bert embedding of a positive/negative keywords list and computing distance(s) of these embedded descriptions to the corresponding cluster, were:
- negative reference: words related to challenges and hazards, which give us a negative sentiment
- positive reference: words related to NBS solutions, strategies, interventions, and adaptations outcomes, which give us a positive sentiment
For modeling purposes, the threshold values adopted are presented in table 1.
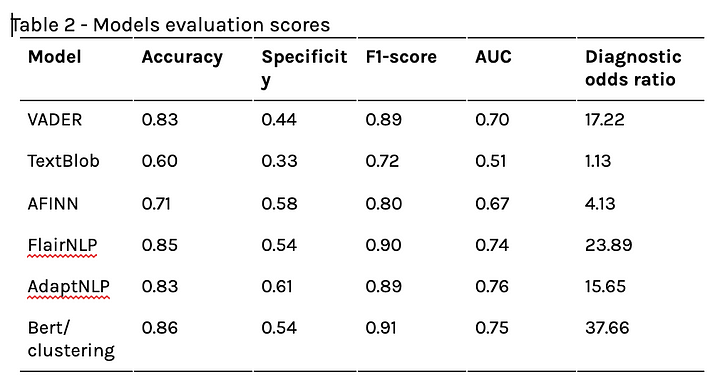
According to the scoring of the models presented in Table 2, AdaptNLP, Flair, and BERT/clustering approaches exhibited better performance compared to the lexicon-based models. Putting the limitations of unsupervised learning aside, BERT/clustering is a promising approach that could be improved for further scaling. SA can be a challenging task, since most algorithms for SA are trained on ordinary-language comments (such as from reviews and social media posts), while the corpus text from the platforms has a more specialized, technical, and formal vocabulary, which raises the need to develop a more personalized analysis, such as the BERT/clustering approach.
Across all organizations, it was observed that the content focuses on solutions rather than gaps. Overall, potential solutions make up 80% of the content, excluding neutral sentiment. Only 20% of the content references potential gaps. Websites typically focus more on potential gaps, while projects and partners typically focus on finding solutions.
Topic modeling
Topic Modeling is a method for automatically finding topics from a collection of documents that best represent the information within the collection. This provides high-level summaries of an extensive collection of documents, allows for a search for records of interest, and groups similar documents together. The algorithms/ techniques that were explored for the project include Top2Vec, SBERT: and Latent Dirichlet Allocation (LDA) with Gensim and Spacy.
- Top2Vec: For which word clouds of weighted sets of words best represented the information in the documents. The word cloud example from Topic Modeling shows that Topic is about deforestation in the Amazon and other countries in South America.
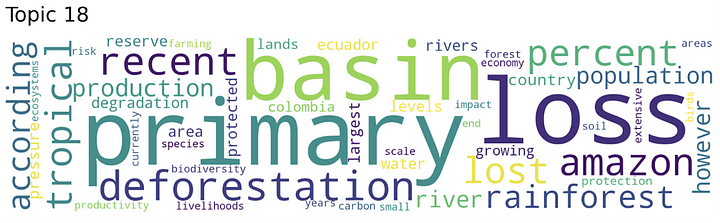
Word cloud generated when a search was performed for the word “deforestation”.
- S-BERT: Identifies the top Topics in texts of projects noted from the three platforms. The top keywords that emerged from each dominant Topic were manually categorized, as shown in the table. The texts from projects refer to Forestry, Restoration, Reservation, Grasslands, Rural Agriculture, Farm owners, Agroforestry, Conservation, Infrastructure in Rural South America.
- LDA: In LDA topic modeling, once you provide the algorithm with the number of topics, it rearranges the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of the topic-keywords distribution. A t-SNE visualization of keywords/topics in the 10k+ unique URLS inside 34 Partner organization websites (partners of AFR100, I20x20, and Cities4Forests) is available on the app deployed via Streamlit and Heroku. The distance in the 3D space among points represents the closeness of keywords/topics in the URL. The color dot represents an organization, hovering over a point provides more information about the Topics referred to in the URL and more. One can further group the URLs by color grouping and analyze the data in greater depth. A t-SNE plot representing dominant keywords indicated from the three platforms’ Partner organization documents. Each color of the dot represents a partner organization.
Other NLP/ML techniques
Besides the aforementioned above, other techniques were also exploited in this project and will be presented in further articles, such as
Network Analysis presents interconnections among the platform, partners, and connected websites. A custom network crawler was created, along with heuristics such as prioritizing NbS organizations over commercial linkages (this can be tuned) and parsing approx. 700 organization links per site (this is another tunable parameter). We then ran the script with different combinations of source nodes (usually the bigger organizations like AFR100, INITIATIVE20x20 were selected as sources to achieve the required depth in the network). Based on these experiments, we derived a master set of irrelevant sites (such as social media, advertisements, site-protection providers, etc.) that are not crawled by our software.
Knowledge Graphs represent the information extracted from the text in the websites based on the relationships between them. A pipeline was built to extract the triplets based upon the subject / object relationship using StanfordNLP’ss OpenIE on the paragraph. Subjects and objects are represented by nodes, and relations by the paths (or “edges”) between them.
Recommendation Systems: The recommender systems application is built based upon the information extracted from the partner’s websites, with a goal to provide recommendations of possible solutions already available and implemented within the network of partners from WRI. The application allows a user to search for similarities across organizations (collaborative filtering) as well as similarities in the content of the solution (content-based filtering).
Question & Answer System: Our knowledge-based Question & Answer system answers questions in the domain context of the text scraped data from the PDF documents from the main platform websites, as well as a few domain-related PDF documents which contain the climate risks and NbS information, as well as the light-scraped data obtained from the platforms and their partner websites.
The KQnA system is based on Facebook’s Deep Passage Retrieval method which provides better context by generating vector embeddings. The RAG neural network(RAG) generates a specific answer for a given question conditioned on the retrieved documents. RAG gives the most of an answer from the shortlisted documents. The KQnA system is built on the open-source Deepset.ai Haystack framework and hosted on a virtual machine, accessible via REST API to the Streamlit UI.
The platform websites have many PDF documents containing extensive significant information that would take a lot of time for humans to process. The Q&A system is not a replacement for human study or analysis but helps ease such efforts by obtaining the preliminary information, linking the reader to the specific documents which have the most relevant answers. The same method was extended to light-scraped data, broadly covering the platform websites and their partner websites.
The PDF and light-scraped documents are stored on two different indices on Elasticsearch to run the query on the streams separately. Deep Passage Retrieval is laid on the Elasticsearch Retriever for contextual search, providing better answers. Filters of Elasticsearch can be applied on the platform/URL for the focused search on a particular platform or website. Elastic search 7.6.2 is installed on VM which is compatible with Deepset.ai Haystack. RAG is applied to the generated answers to get a specific answer. Climate risks, NbS solutions, local factors, and investment opportunities are queried on PDF data and Platform data. Questions on the platform for PDF data, URL for light scraped data can be performed for localized search.
Insights
By developing decision-support models and tools, we hope to make the NbS platforms’ climate change-related knowledge useful and accessible for partners of the initiative, including governments, civil society organizations, and investors at the local, regional, and national levels.
Any of these resources can be augmented with additional platform data, which would require customizing the data gathering effort per website. WRI could extend the keywords used in statistical analysis for hazards, the types of interventions, the types of ecosystems, and create guided models to gain further insights.
Data gathering pipeline
We have provided very useful utilities to collect and aggregate data and PDF content from websites. WRI can extend the web-scraping utility from the leading platforms and their partners to other platforms with some customization and minimal effort. Using the PDF utility, WRI can retrieve texts from any PDF files. The pre-trained multilingual model in the translation utility can translate the texts from various sources to any language.
Statistical analysis
Using zero-shot classification, predictions were made for the keywords that highlight Climate Hazards, Types of Interventions, and Ecosystems, based upon a selected threshold. Cosine similarity predicts the similarity of a document with regard to the keywords. Heat maps visualize both of these approaches. A higher similarity score means the organization is more associated with that hazard or ecosystem than other organizations.
Sentiment analysis
SA identifies potential gaps from negative connotations derived from words related to challenges and hazards. A tree diagram visualizes the sentiment analysis for publications/partners/projects documents from each platform. Across all organizations, the content focuses on solutions rather than gaps. Overall, solutions and possible solutions make up 80% of the content, excluding neutral sentiment. Only 20% of the content references potential gaps. Websites typically focus more on potential gaps, while projects and partners typically focus on finding solutions.
Topic Models
Topic models are useful for identifying the main topics in documents. This provides high-level summaries of an extensive collection of documents, allows for a search for records of interest, and groups similar documents together.
- With semantic search with Top2Vec. For which word clouds of weighted sets of words best represented the information in the documents. The word cloud example from Topic Modeling shows that Topic is about deforestation in the Amazon and other countries in South America.
- S-BERT: Identifies the top Topics in texts of projects noted from the three platforms. The top keywords that emerged from each dominant Topic were manually categorized, as shown in the table. The texts from projects refer to Forestry, Restoration, Reservation, Grasslands, Rural Agriculture, Farm owners, Agroforestry, Conservation, Infrastructure in Rural South America.
- In LDA topic modeling, once you provide the algorithm with the number of topics, it rearranges the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of the topic-keywords distribution.
- A t-SNE visualization of keywords/topics in the 10k+ unique URLS inside 34 Partner organization websites (partners of AFR100, Initiative 20×20, and Cities4Forests) is available on the app deployed via Streamlit and Heroku.
- The distance in the 3D space among points represents the closeness of keywords/topics in the URL
- The color dot represents an organization, hovering over a point provides more information about the Topics referred to in the URL and more.
- One can further group the URLs by color grouping and analyze the data in greater depth.
- A t-SNE plot representing dominant keywords indicated from the three platforms’ Partner organization documents. Each color of the dot represents a partner organization.
This work has been part of a project with World Resources Insitute.
—
This article is written by Bala Priya, Simone Perazzoli, Nishrin Kachwala, Anju Mercian, Priya Krishnamoorthy, and Rosana de Oliveira Gomes.
Want to work with us?
If you want to discuss a project or workshop, schedule a demo call with us by visiting: https://form.jotform.com/230053261341340
Related Articles



