
Rooftop Detection on Low-Resolution Images with Mask R-CNN Model
April 28, 2020

The problem
The complexity of the task is increased due to the quality of satellite images from India (and most of the developing world). Similar solutions like the Google Sunroof project work only on high-resolution images and are not usable in the majority of the developing world.
Mask R-CNN was built by the Facebook AI research team. The working principle of Mask R-CNN is quite simple. The researchers combined two previously existing models together and played around with the linear algebra. The model can be divided into two parts — a region proposal network (RPN) and a binary mask classifier. Step one is to get a set of bounding boxes that possibly contain an object of relevance. The second stage is to color the boxes.
Our goal of using this model is to segment or separate each roof-top instance in an image.

Example of outputs
Our challenges started with the lack of data as there are no datasets with rooftops.
We used weights from Mask R-CNN network trained over “coco” dataset that was originally trained to recognize 80 classes but did not have a roof, as a starting point for our model. Resnet 101 was used as a backbone architecture. We started with training our model for “heads” layers, i.e. the RPN, classifier and mask heads of the network; because training the entire network would need a lot of data and since it was pre-trained model over many different classes, it would be a good start. Then to see the difference it made in prediction, we moved up to training till stage 4 and 5 of Resnet 101 architecture.
We also tried different variations. Image size was changed from 1024X1024 to 320X320 because our training image size is 300X300 and padding didn’t seem a good idea to increase it up to 1024.

Multiple models that we used with changing image size and processing
Results from input images

Original Image (1)


Original Image (2)
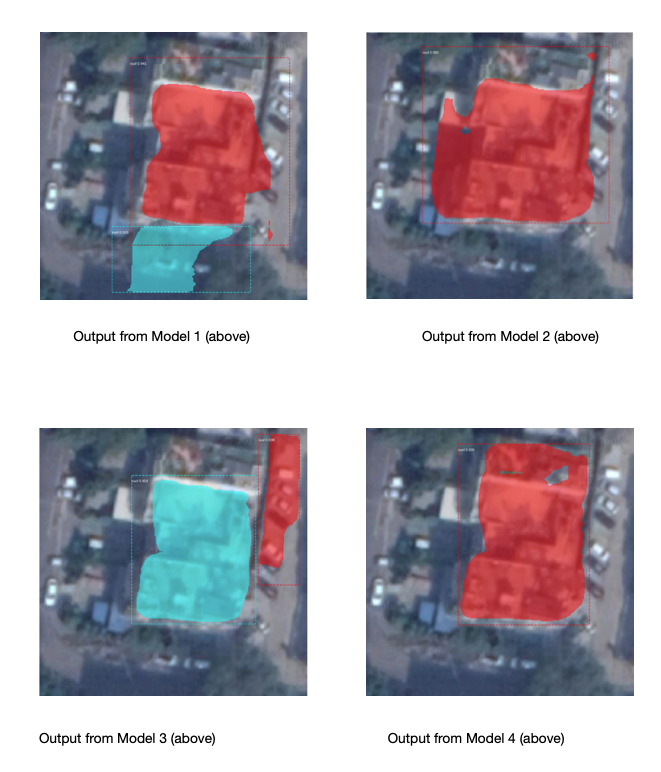
We compared results from another 20 rooftops and our results show that often the model 4 performs best.
We then tried changing the minimum detection confidence threshold, from 0.9 to 0.7. Regions of Interest(ROIs) below this value will be skipped. It was done because for detecting roofs, 0.9 seemed a very high threshold when it can just be reduced enough to predict any region as a rooftop, as roofs aren’t intricate, well-defined and very specific regions; so any region that can be a good candidate for rooftop should be considered. At 0.7 we had a lot more regions but it also presented us with many overlapped regions as roofs whereas, for 0.9 value, we had a few big blobs taking all of the adjacent roofs as one region.

Detection confidence 0.7

Detection confidence 0.9
Other than this, we were trying to train the model by changing the optimizer from Stochastic Gradient Descent(SGD) to Adam optimizer.
Here are the result images for models trained with SGD and Adam optimizer. Training is done with 70% and 90% confidence. Testing is done with 70% and 90% confidence for each of the trained models.

Adam Optimizer 0.7 threshold
SGD 0.7 threshold

Adam Optimizer threshold 0.7

SGD threshold 0.7
Our Findings
1. Adam optimizer trained models are not able to predict all the instances and they are not able to differentiate between the adjacent roofs as compared to SGD trained models.
2. SGD trained models predict sharper masks than the Adam trained models. This shows SGD is better for our models, and we’ll continue with it.
About SGD variations:
1. Training the model with 70% confidence is increasing the number of masks, as it has been trained to consider low probability roofs too which leads to overlapped masks. Whereas training with 90% is giving cleaner and fewer masks. So, training with 90% seems a better option.
2. Now, to predict masks with 70% confidence or with 90% confidence? 90% is too precise and might remove other options whereas 70% will include them as seen in images 4 and 7. So, after training for more number of images(currently trained over 95 images), we will be able to see which one can be used finally.
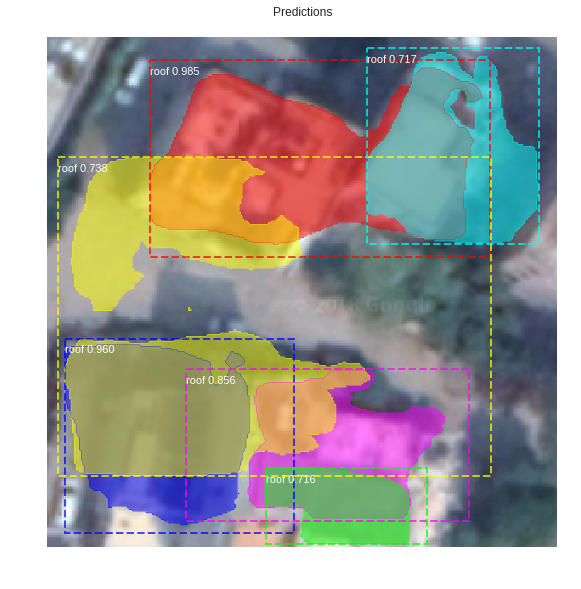
As a final step to identify the individual rooftops we did some post-processing. We created regular shapes from the odd colored shaped. The post-processing was done on a dataset of 607 images.

Output from Masked R-CNN

Individual rooftops




You might also like
Want to work with us too?



