
Exploring Scientific Literature on Online Violence Against Children Using Natural Language Processing
Exploring scientific literature on online violence against children through Natural Language Processing and text analysis.

November 23, 2020
14 minutes read

Textual Data – A Trove of Information
The amount of information available in the world is increasing exponentially year by year and shows no signs of slowing. This rapid increase is driven by expansions in physical storage and the rise of cloud technologies, allowing more data to be exchanged and preserved than ever before. This boom, while great for scientific knowledge, also has possible downsides. As the volume of data grows, so also does the complexity in managing and extracting useful information from it.
More and more, organizations are turning to electronic storage to safeguard their data. Unstructured textual information like newspapers, scientific articles, and social media is now available in unprecedented volumes.
It is estimated that about 80% of enterprise data currently in existence is unstructured data, and this continues to increase at a rate of 55–65% per year.
Unstructured data, unlike structured data, does not have clearly defined types and isn’t easily searchable. This also makes it relatively more complex to perform analysis on.
Text mining processes utilize various analytics and AI technologies to analyze and generate meaningful insights from unstructured text data. Common text mining techniques include Text Analysis, Keyword Extraction, Entity Extraction/Recognition, Document Summarization, etc. A typical text mining pipeline includes data collection (from files, databases, APIs, etc.), data preprocessing (stemming, stopwords removal, etc.), and analytics to ascertain patterns and trends.
Just as data mining in the traditional sense has proven to be invaluable in extracting insights and making predictions from large amounts of data, so too can text mining help in understanding and deriving useful insights from the ever-increasing availability of text data.
Natural Language Processing (NLP) can be thought of as a way for computers to understand and generate human natural language. This is possible by simulating the human ability to comprehend natural language. NLP’s strength comes from the ability of computers to analyze large bodies of text without fatigue and in an unbiased manner (note: unbiased refers to the process, it is possible for the data to be biased).
Online Violence Against Children
As of July 2020, there are over 4.5 billion internet users globally, accounting for over half of the world’s population. About one-third of these are children under the age of 18 (one child in every three in the world). As these numbers rise, sadly, so too does the number of individuals looking to exploit children online. The FBI estimates that at any one time, there are about 750,000 predators going online with the intention of connecting with children.
For our project, we wanted to explore how text mining and NLP techniques could be applied to analyzing the scientific literature on online violence against children (OVAC). We picked scientific articles as our focus, as these can provide a wealth of information — from the different perspectives that have been used to study OVAC (i.e. criminology, psychology, medicine, sociology, law), to the topics that researchers have chosen to focus on, or the regions of the world where they have dedicated their efforts. Text mining allowed us to collect, process, and analyze a large amount of published scientific data on this topic — capturing a meaningful snapshot of the state of scientific knowledge on OVAC.
Data Collection and Preprocessing
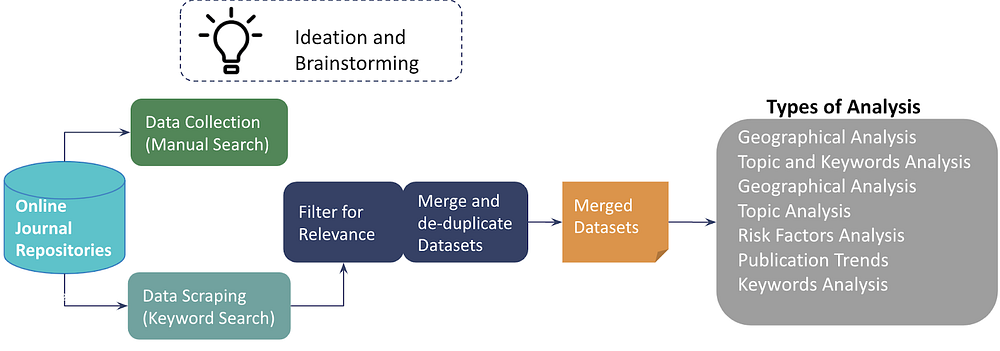
Our overall process flow from data collection to analysis
Our first step was to collect datasets of articles that we could find online. The idea was to scrape a variety of repositories for scientific articles related to OVAC, using a set of keywords as search terms. We built scrapers for each repository, making use of the BeautifulSoup and Selenium libraries. Each scraper was unique to the repository and collected information such as the article metadata (i.e Title, Authors, Publisher, Date Published, etc.), the article Abstract, and the article full-text URL (where available). We also built a script to convert the full-text articles from PDF to Text, using Optical Character Recognition (OCR). Only one of the repositories, CORE, had an API that directly allowed us to scrape the full text of the articles.
Having collected over 27,000 articles across 7 repositories, we quickly realized that many articles were not relevant to OVAC. For example, there were many scientific articles about physical sexual violence against children, that also mentioned some sort of online survey. These articles fulfilled the “online AND sexual AND violence AND children” search term but were irrelevant to OVAC. Hence, we had to manually filter the scientific articles for relevance, sieving out 95% of articles that were not related to OVAC.
Faced with such a painfully manual task, some members of the team tried out semi-automated methods of filtering. One method used clustering to find groups of papers that were similar to each other. The idea was that relevant papers would show up in the same group, while irrelevant papers would show up in their own groups. We would then only need to sift through each cluster instead of going through each individual paper, saving almost 10–30 times the effort. However, this assumed perfect clusters, which was often not true. The clustering method was definitely faster and filtered out 41% of articles, but it also left more irrelevant articles undetected. An alternative to clustering would be to train classifiers to identify relevant articles based on a set of pre-labeled articles. This could potentially work better than clustering, but having undetected articles still remains a limitation.
One of the perks of working with scientific articles (read: texts that have been reviewed rigorously) is that minimal data cleaning is required. Steps that we would otherwise have to take when dealing with free texts (e.g. translating slang, abbreviations, and emojis, accounting for typos, etc.) are not needed here. Of course, text pre-processing steps like stemming, stop-word removal, punctuation removal, etc. are still required for some analysis, like clustering or keyword analysis.
Drawing insights from text analysis regarding online violence against children
Armed with a set of relevant articles, the team set off to discover the various types of methods to extract insights from the dataset. We attempted a variety of methods (i.e. TF-IDF, Bag of Words, Clustering, Market Basket Analysis, etc.) in search of answers to a set of questions that we aimed to explore with the dataset. Some analyses were limited by the nature of the datasets (e.g. in keywords analysis, there is a lot of noise and random words in the data. Some trends/patterns emerge but it is not very conclusive), while others showed great potential in picking out useful insights (e.g. clustering, market basket analysis as described below).
Keywords Analysis
Based on the title and abstract texts, we were able to generate a word cloud of the most frequent terms appearing in the OVAC scientific literature. We also used TF-IDF vector analysis to explore the most relevant words, bigrams, and trigrams appearing in the title and abstract texts in each publication year. This allowed us to chart the rise of certain research topics over time — for example around the years 2015 and 2016, terms related to “travel” and “tourism” began to appear more often in the OVAC literature, suggesting that this problem received greater research attention in this period
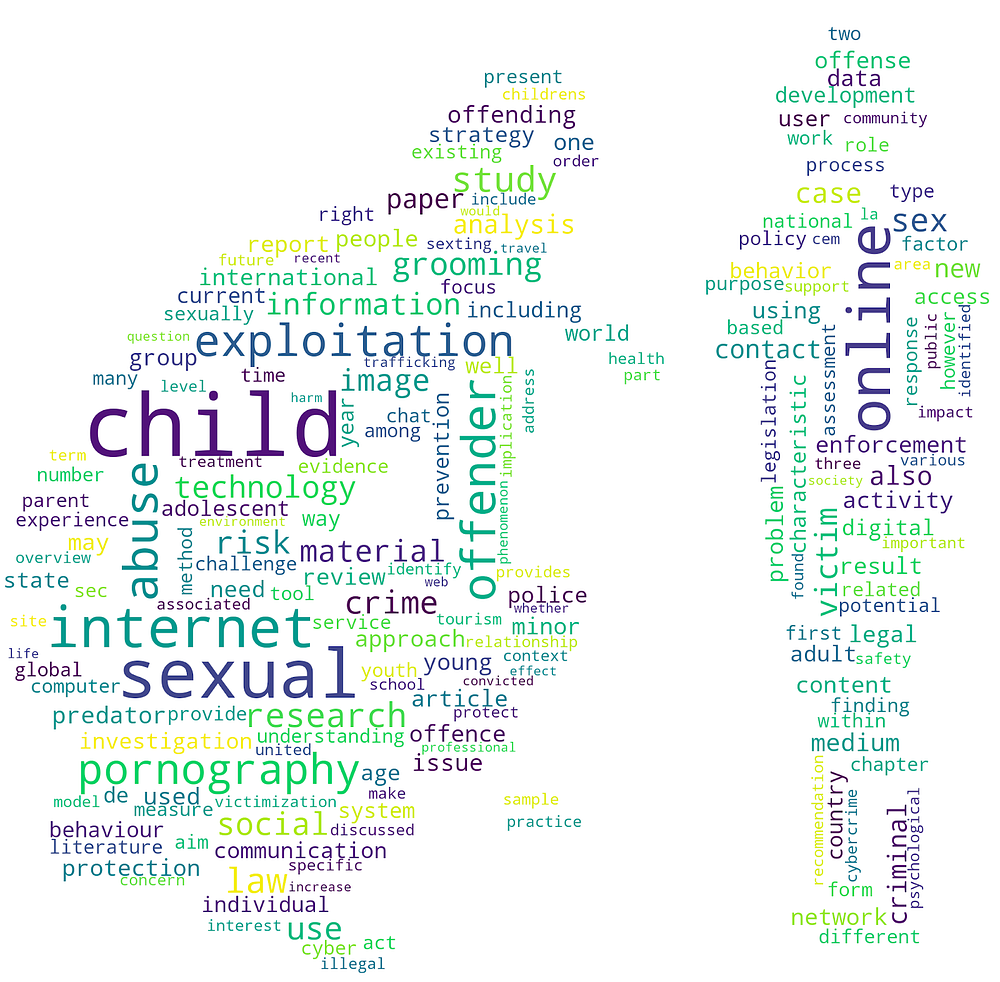
Word cloud of title and abstract texts from over 1300 scientific articles on online violence against children. Source. www.omdena.com
Geographical Market Basket Analysis
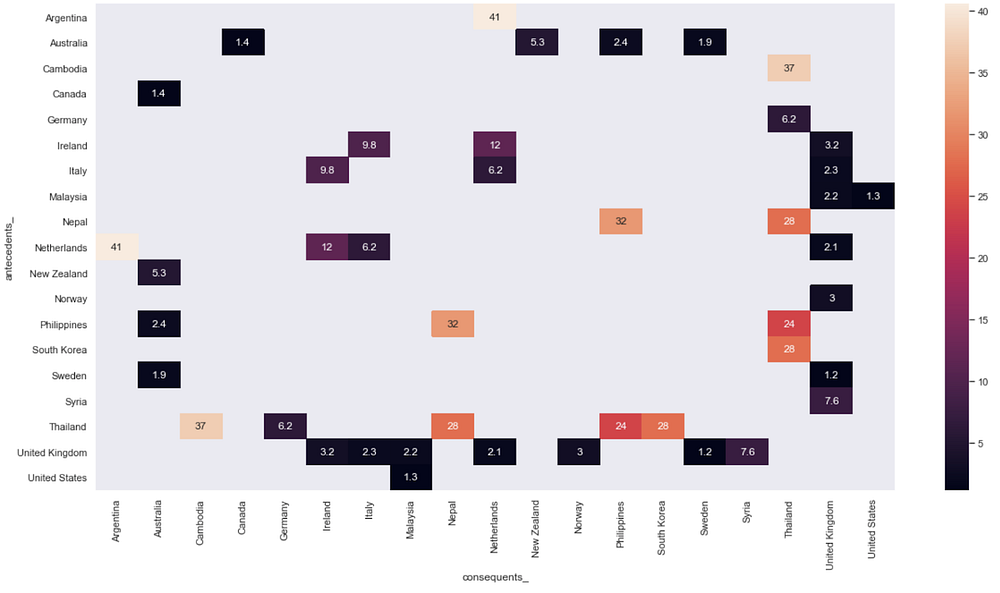
Heat map of the Lift between country pairs. A lift of more than 1 suggests that the presence of one country increases the probability that the other country will also appear in the article. The larger the lift, the more likely they would appear together.
We conducted a Market Basket analysis to find out which countries were likely to appear in the same article. This could potentially give insight to the networks of countries involved in OVAC. While we noticed that many countries appear together because they were geographically close, there were also exceptions.
From the heat map above, this includes country pairs like Malaysia-US, Australia-Canada, Australia-Philippines, and Thailand-Germany. Upon investigation, we found that:
- Most articles contain these pairs because of exemplification.
- Some are mentioned as a breakdown of countries where respondents of surveys and studies were conducted. (E.g. Thailand and Germany were mentioned as part of a 6-country survey of adolescents.)
- More interestingly, there were also articles that mentioned pairs of countries due to offender-victim relationships. (E.g. an article studying offenders in Australia mentioned that they preyed on child victims in the Philippines.)
Topics Clustering Analysis
Another of our solutions used machine learning to separate the documents into different clusters defined by topics. A secondary motive was to explore the possibility that the different documents can form a network of communities not only based on their topics, but also on how the documents relate to each other.
The Louvain Method for community detection is a popular clustering algorithm used to understand the structure, as well as to detect communities of large networks. The TF-IDF representation of the words in the vocabulary was used to build a co-occurrence matrix containing the cosine similarities between each document. The clustering algorithm detected 5 distinct communities.
A manual inspection of the documents in each cluster suggested the following topics –
- Institutional, Political (legislative) & Social Discourse
- Online Child Protection — Vulnerabilities
- Technology
- Analysis of Offenders
- Commercial Perspective & Trafficking
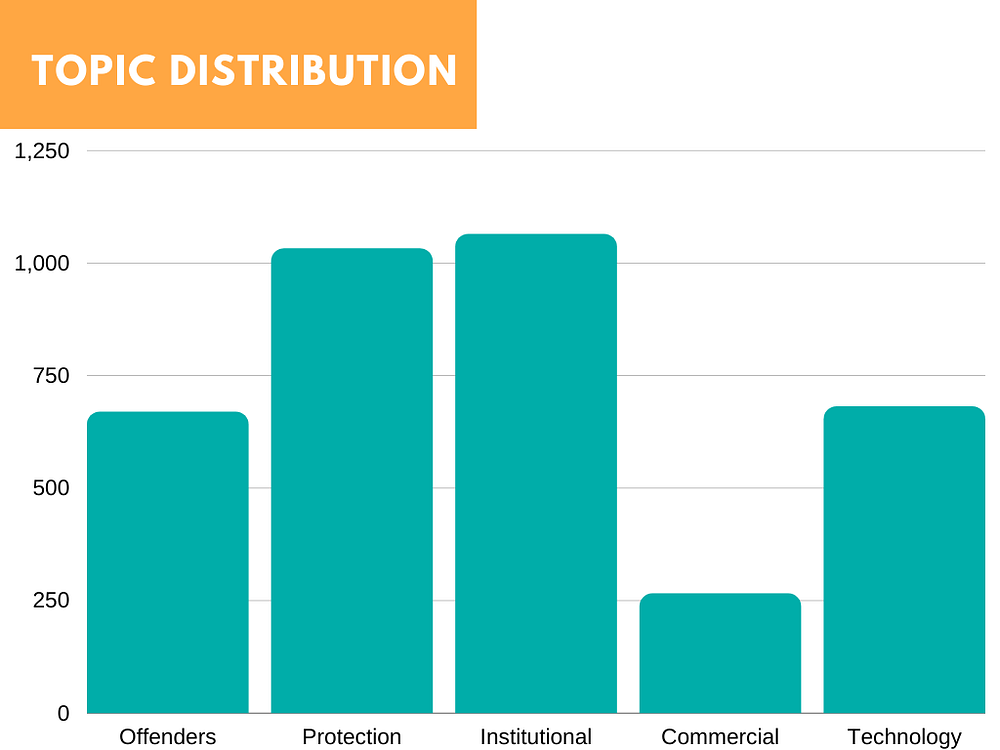
Bar chart of Frequency of Articles by Topic
The first two topics appear to be the most published while Commercial Perspective & Trafficking is the least. The cluster and structure detected by the clustering algorithm we noticed, could be visualized in the shape of a Graph Network. The articles were represented as nodes, and nodes of the same topic are grouped together and colored the same, the strength of the relationship between nodes as defined by the cosine similarity is represented by links/edges. Below is a visual representation of the structure of the Graph Network:
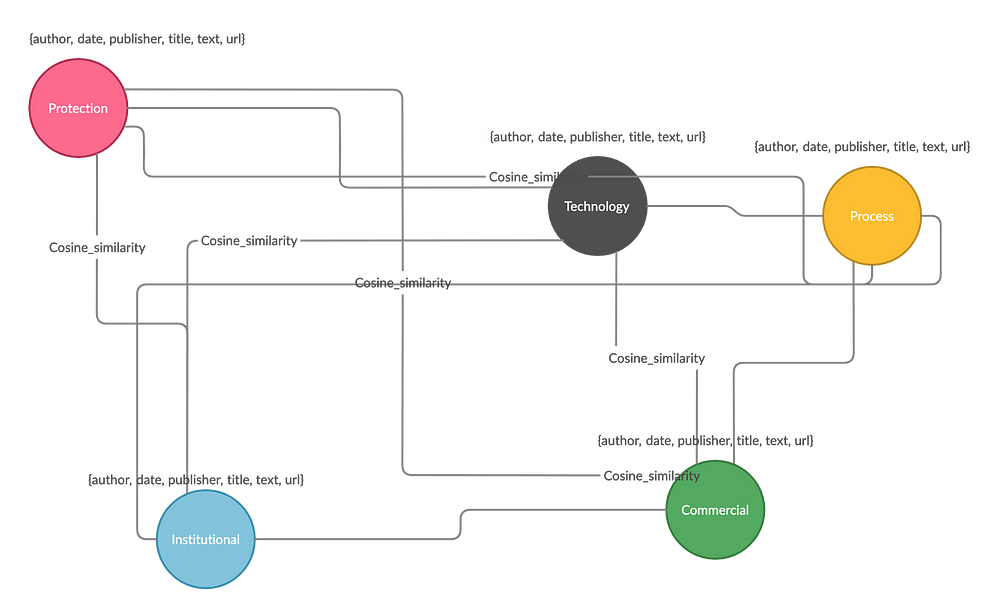
Structure of Graph Network — Articles were labeled according to community detection clustering and relationships defined by the cosine similarity between the documents. Other information like the text, date, published data, and URL of the papers were stored as properties of the nodes (vertices), and the links (edges) were defined as the cosine similarity value between documents.
One advantage of restructuring the data in this manner is that it allows the data to be stored in a Graph Database. Traditional relational databases work exceptionally well at capturing repetitive and tabular data, they don’t do quite as well at storing and expressing relationships between the entities within the data elements. A database that embraces this structure can more efficiently store, process, and query connections. Complex analysis can be done on the data by using a pattern and specifying starting points. Graph Databases can efficiently explore connecting data to those initial starting points, collecting and processing information from nodes and relationships while leaving out data outside the search pattern.
Challenges and Limitations
The major challenges we faced were related to compiling our dataset. Only one of the repositories we used, CORE, granted API access which greatly sped up the process of obtaining data. For the rest, the need to build custom scraping scripts meant that we could only cover a limited number of repositories. Other open repositories, such as Semantic Scholar, resisted our scraping efforts, while others such as Web of Science or ESBSCOhost, are completely walled-off to non-subscribers. The great white whale of scientific article repositories, Google Scholar, also eluded us. Here, search results are purposefully presented in such a way that it is not possible to extract the full abstract texts — although some other researchers with a lot of time and effort have had greater success with scraping it.
As shown, we were able to conduct a range of interesting and meaningful analyses using just the abstracts of the scientific articles, but to go further in our research would require overcoming the challenges related to obtaining the full text of the scientific articles. Even after developing a custom tool to extract text from PDFs, we still faced two challenges. Firstly, many articles were paywalled and could not be accessed, and secondly, the repositories we scraped did not systematically link to the PDF page of the article, so the tool could not be utilized across our whole dataset.
If a would-be data scientist is able to surpass all these hurdles, a final barrier to extracting information from scientific articles remains. The way in which scientific texts are structured, with sections such as “Introduction”, “Methodology”, “Findings” and “Discussion”, varies greatly from one article to the next. This makes it especially difficult to answer specific questions such as “What are the risk factors of being an offender of OVAC” that require searching for information in a specific section of the text, although it is less of an issue if you are seeking to answer more general questions, such as “How has the number of research papers changed over time?”. To overcome the difficulty of extracting specific information from unstructured text, we built a Neural Search Engine powered by haystack that uses a distilbert transformer to search for answers to specific questions in the dataset. However, it is currently a proof-of-concept and requires further refinement to reach its full potential of being able to answer the questions accurately.
These challenges create some limitations for the findings of our analysis. We cannot say that our dataset captures the entirety of scientific research into online violence against children, but rather just that which was contained in the repositories that we were able to access — we do not know if this could bias our results in some way (for example, if these repositories were more likely to contain papers from certain fields, or from certain parts of the world). It is worth noting that we conducted all of our searches in English. Fortunately, scientific article abstracts are often translated, so we were able to analyze the text of these, even when the original language of the article was different.
Another limitation is that as scientific knowledge increases over time, more recent articles could be more relevant than historical ones if certain theories or assumptions are later found to be incorrect with further research. However, all articles were given equal weight in our analysis.
Given the challenges that we faced with accessing repositories and articles and the incalculable benefits of greater data openness in scientific research, it is interesting to discuss an initiative that is working toward that goal. A team at Jawaharlal Nehru University (JNU) in India is building a gigantic database of text and images extracted from over 70 million scientific articles. To overcome copyright restrictions, this text will not be able to be downloaded or read, but rather only queried through data mining techniques. This initiative has the potential to radically transform the way that scientific articles are used by researchers, opening them up for exploration using the entirety of the data science toolkit.
Conclusion
We have demonstrated in this case study how text mining and NLP techniques can aid the analysis of scientific literature at every step of the way — from data collection to cleaning and to gain meaningful insights from text. While full texts helped us to answer more specific questions, we found that using just abstracts was often sufficient to gain useful insights. This shows great potential for future abstract-only analysis in cases where access to full-text articles is limited.
Our work has helped Save the Children to understand OVAC and its research space better, and similar types of analysis can benefit other NGOs in many ways. These include:
- understanding a topic
- having an overview of the types of research efforts
- understanding research gaps
- identifying key resources (e.g. datasets often quoted in papers, most common citations, most active researchers/publishers, etc.)
There are also many other possibilities of NLP methods to extract insights from scientific papers that we have not tried. Here are some ideas for future exploration:
- Extracting sections from scientific articles — articles are organized in sections, and if we can figure out a way to split articles up into sections, it would be a great first step towards a more structured dataset!
- Named Entity Recognition — From figuring out which entities are being discussed to using these to answer specific questions, NER unlocks a ton of possible applications.
- Network Analysis using Citations — This could be an alternative method to cluster the articles, or it could also help to identify the ‘influential’ articles or map out the progress of research.
This article is written by Wen Qing Lim, Maria Guerra-Arias, Sijuade Oguntayo.


