
How NLP and AI Helped NGOs Unlock Billions in Grant Funding
Discover how Omdena used NLP and AI to help NGOs access billions in funding through automation, data analysis, and interactive dashboards.

Why NGOs Struggle with Grant Discovery and How NLP Helps
Artificial Intelligence (AI) and Natural Language Processing (NLP) are transforming how NGOs access and use funding information. By applying NLP techniques, organizations can make sense of massive amounts of unstructured data from PDFs, social media, and search results to uncover actionable insights.
In this project, we developed an automated NLP pipeline that scraped and analyzed information from Twitter, Google, and more than 1,200 PDF documents using APIs. This process produced a dataset that captured several billion dollars in global grant data across six countries. The final outcome was an interactive dashboard that visualized the distribution of these grants and provided valuable insights for NGOs seeking funding.
Traditional methods of discovering grants are often slow, expensive, and limited in scope. Similar approaches have shown that AI-supported grant workflows can cut proposal preparation and early-stage grant research time by up to 50%, allowing NGOs to redirect effort toward program delivery rather than administration. Our approach demonstrated how NLP can simplify data collection, speed up analysis, and make information more transparent for nonprofits that rely on timely funding decisions.
This article walks through our full process from gathering unstructured data to feature engineering and final visualization showing how NLP can help NGOs bridge the gap between data and impact.
Applying NLP to NGO Grant Discovery
Every year, governments, philanthropies, private organizations, and other funders distribute billions of dollars in grants to support global causes. Yet, many nonprofits still struggle to access these funds. The main reason is the lack of transparency and the difficulty in finding reliable, organized grant information.
In Australia alone, an estimated $80–90 billion (AUD) in grants is disbursed each year. However, a large portion of NGOs miss out on funding simply because the information is scattered and hard to track.
To address this issue, Our Community, a social enterprise that provides digital tools and resources for the social sector, partnered with Omdena’s AI community. Together, we set out to transform how grant information is collected, analyzed, and shared. The goal was to make funding data accessible, clear, and actionable for every nonprofit — especially smaller organizations with limited resources.
Traditional methods of finding and monitoring grants often require extensive manual research. These processes are time-consuming, costly, and prone to human error. By applying NLP and automation, our goal was to bridge this gap and help connect grantmakers with NGOs more effectively.
Through this collaboration, we aimed to:
-
Reduce the time required for NGOs to discover relevant grants.
-
Centralize funding data from multiple sources.
-
Create a transparent system that visualizes where grant money is flowing.
This project was more than a technical challenge — it was an opportunity to empower NGOs with the tools they need to unlock funding and amplify their social impact.
Finding the Data: The Core Challenge Behind Building the AI Solution
Every AI project depends on data — and in most real-world problems, that’s where the biggest challenge begins.
When we started, we realized that the data we needed didn’t exist in a structured format. Like most social impact problems, the real information was scattered across thousands of documents, reports, and websites. Without this data, even the most advanced AI algorithms would be ineffective.
Data is growing at an incredible rate every minute, but most of it is unstructured — hidden inside PDFs, articles, and social media posts. For years, this kind of data was often ignored because it’s difficult to process. However, since most human knowledge lives in unstructured form, it can no longer be overlooked.
That’s exactly where Natural Language Processing (NLP) comes in. NLP is a branch of artificial intelligence that allows computers to understand and interpret human language. By applying NLP, we can convert text-heavy data into structured, machine-readable insights that NGOs can actually use.
In this project, we focused on extracting and cleaning unstructured data to prepare it for NLP analysis. Our goal was to turn raw, tangled information into clear, actionable intelligence that reveals where funding is available — and how it can reach the organizations that need it most.
How We Collected the Unstructured Data
Most of the useful data was stored in PDF format. These files contained valuable insights that could not be ignored. However, we were faced with more than 1,200 PDFs that needed to be downloaded and processed from various sources. Doing this manually would have taken weeks, so automation was the only practical solution.
To make this possible, we designed a microservice that automatically handled data collection using RESTful APIs. This system allowed us to download, parse, and organize thousands of files with minimal manual effort.
Flask to quickly develop small web-based applications
We used the Flask framework to create RESTful APIs and deployed them on AWS EC2 as a containerized service with Docker. The process began with uploading a CSV file that contained links to all the PDF documents.
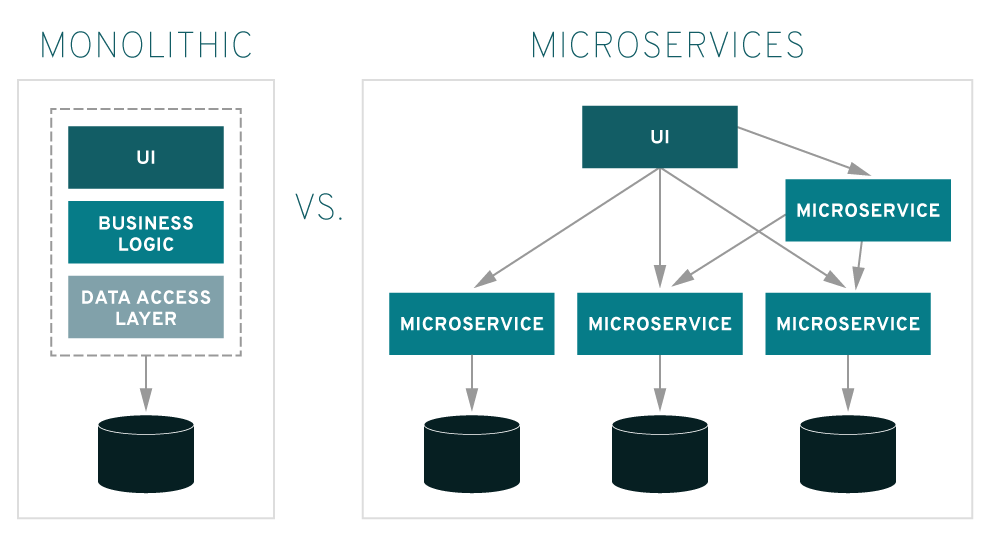
Monolithic vs Microservices pipelines – Source: RedHat
That’s the great thing about microservices; they are standalone programs that can be developed and readily deployed to be made available to different users. We wanted our code to be reusable so developing the microservice to use RESTful APIs seemed like a no-brainer. Flask is a python based micro-framework that comes in handy when needed to quickly develop small web-based applications.

Google search workflow in NLP
Once uploaded, the microservice automatically downloaded the PDFs, parsed their contents using GROBID, and stored the extracted text in a single consolidated file. Finally, this cleaned and structured data was uploaded to AWS S3 for further processing.
Microservices are independent programs that can be developed, reused, and deployed quickly. This approach made the system modular and scalable so multiple teams could use it without conflicts. Flask, being a lightweight Python framework, was ideal for building and deploying this kind of flexible solution efficiently.
.
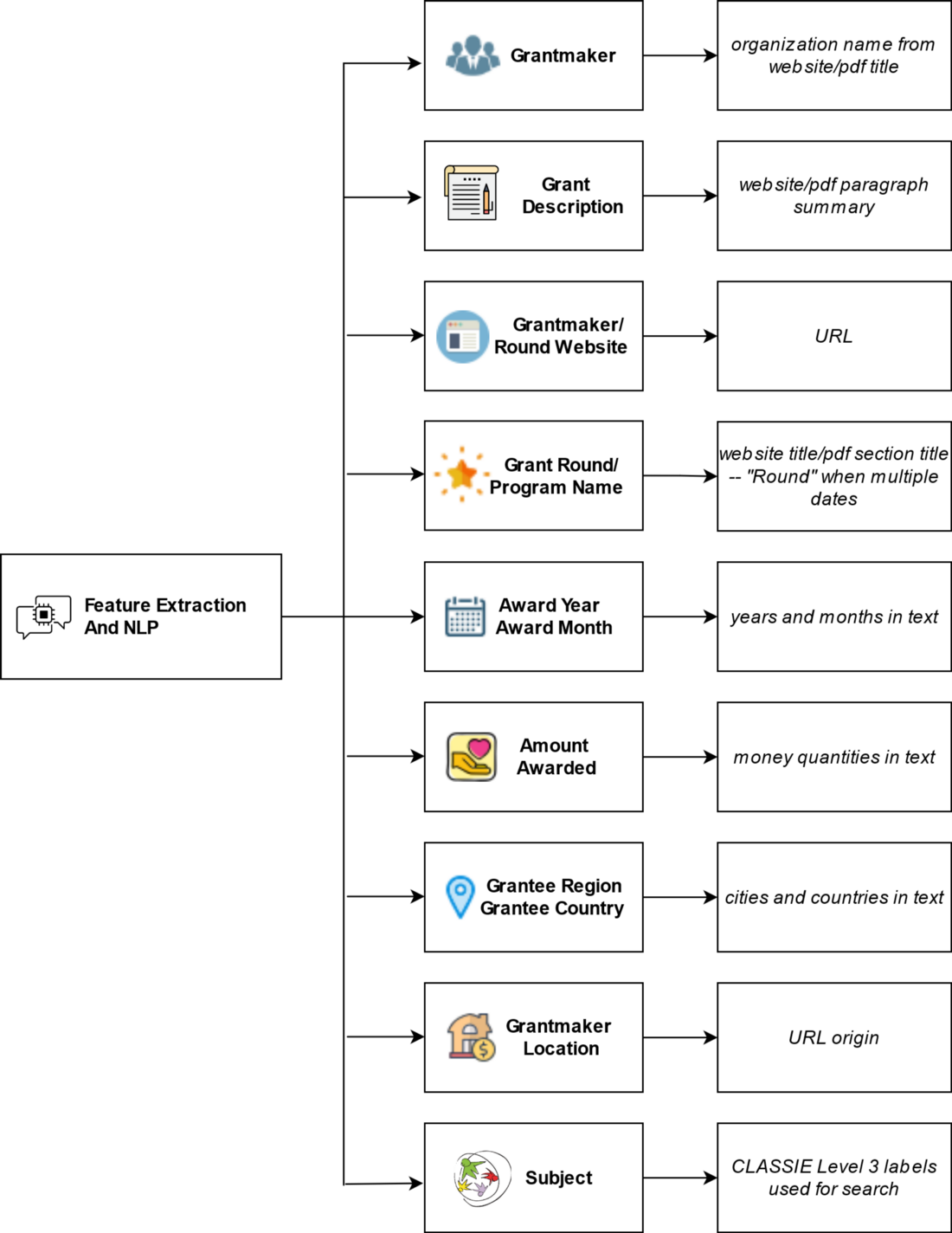
Features extracted and preprocessing
With the data successfully stored and ready for use, the next step was feature extraction and preprocessing. By automating the data extraction process, we turned what could have been a complex, time-consuming task into a streamlined system capable of handling large volumes of unstructured data with precision and speed.
From Data to Insights: NLP Analysis and Visualization
At this stage, after completing data collection and feature extraction, we began analyzing and visualizing the results. The goal was to make the data easy to understand and accessible for anyone interested in how grants are distributed globally.
Creating the Dashboard
We used Streamlit and Plotly to build an interactive dashboard that displayed the structured data visually. This dashboard allowed users to explore the dataset dynamically, filter information, and identify funding trends across regions and sectors.
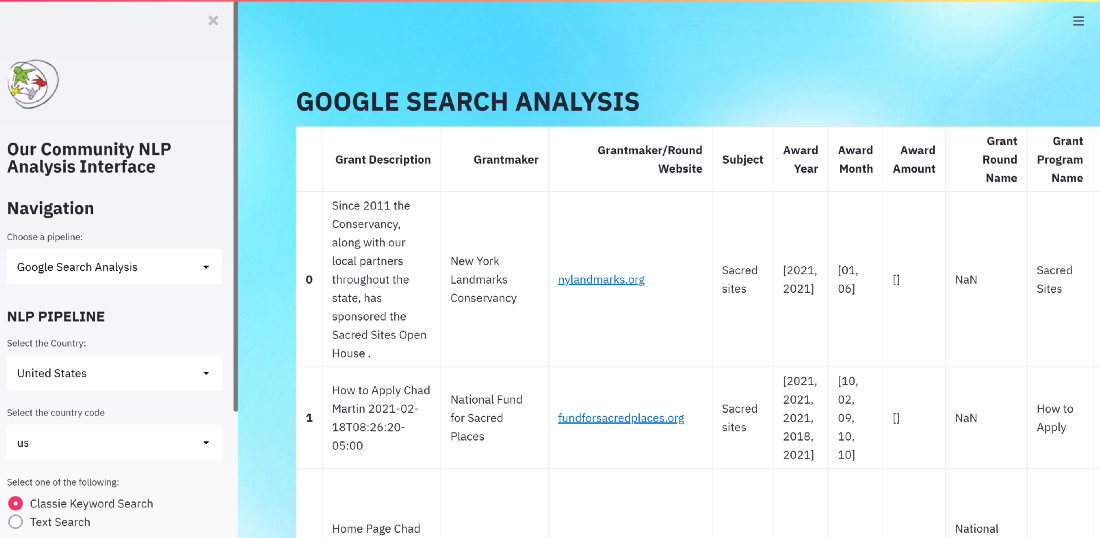
Extracted Feature set from Apify – Source: Omdena
The interface made it possible to:
- View the total value of grants distributed.
- Identify key countries and organizations involved in funding.
- Analyze the flow of money between grantmakers and nonprofits.
- Highlight funding gaps and potential opportunities for collaboration.
By transforming the processed data into an interactive dashboard, we helped make insights visible and actionable. Users could now see patterns that were previously hidden in thousands of pages of text.
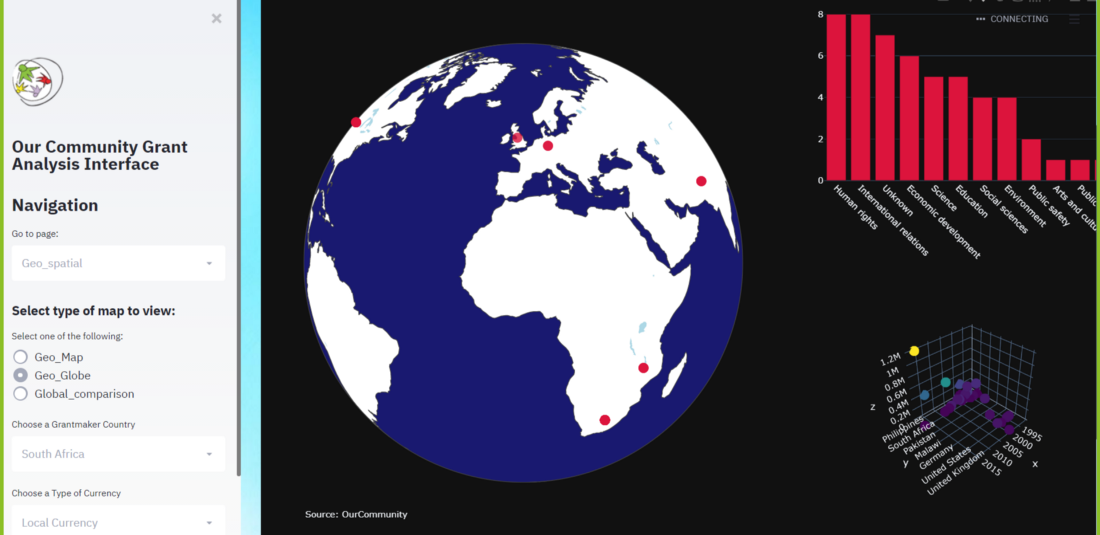
Interactive dashboard showing the distribution of grants extracted by NLP analysis – Source: Omdena
Integrating Structured and Unstructured Data
In addition to processing unstructured data through NLP, we also collected structured data from websites that published grant information in tables. To achieve this, our team created custom site-specific scrapers that automatically extracted this data. Combining structured and unstructured datasets resulted in a more complete and reliable picture of the funding landscape.
The Final Outcome
The overall approach enabled us to analyze and visualize several billion dollars in nonprofit grant data across six countries. This type of system reflects a broader digital transformation shift within NGOs, where data integration, automation, and analytics are increasingly used to improve transparency, coordination, and decision-making at scale. The dashboard provided clear visibility into how funds are distributed, which organizations receive them, and where potential funding gaps exist.
This solution demonstrated how NLP, automation, and visualization can work together to promote transparency, efficiency, and accessibility in the nonprofit funding ecosystem.
One Shared Mission Behind the Project
The project came to life through the collective effort of more than 50 AI engineers and data scientists who worked together over eight weeks. Each contributor brought a unique set of technical skills and a shared motivation to create solutions that would help NGOs access funding more effectively.
Team coordination
From the very beginning, the team followed a clear mission: to use AI for social good. Each week involved coordination, code reviews, data validation, and continuous feedback sessions. This strong collaboration allowed the group to overcome technical challenges quickly and maintain high standards throughout the project.
The success of this initiative proved that when diverse talent comes together around a common purpose, innovation happens faster and impact grows deeper. The project not only advanced technical outcomes but also strengthened community-driven problem solving.
Real-world impact of the solution
Thanks to this effort, Our Community and Omdena delivered an AI-powered solution that helps NGOs identify and access grants faster. The solution improved transparency in the funding ecosystem and reduced time spent searching for opportunities.
For many NGOs, this means being able to focus more on their missions rather than administrative work. The combination of NLP, automation, and open collaboration created a new model for how technology can directly empower the nonprofit sector.
Acknowledgment
This project was made possible through the dedication of Our Community, Omdena task managers, and all collaborators who contributed their time and expertise. Their commitment transformed complex data into meaningful insights and tangible outcomes for organizations in need.
This collaboration proved that advanced technologies like NLP can drive real social impact when guided by purpose and teamwork. It stands as a model for how data science can unlock new opportunities for global good.
Conclusion
This project demonstrates how NLP and automation can turn fragmented, text-heavy grant data into clear, actionable insights for NGOs. By analyzing billions of dollars in global funding information and reducing manual research time by more than half, the solution provides nonprofits with a faster and more transparent way to identify relevant opportunities and understand funding flows.
With a reliable AI-powered system in place, NGOs can shift their focus away from time-consuming data discovery and toward delivering impact on the ground. The combination of NLP, automation, and visualization shows how well-designed AI solutions can strengthen decision-making, improve access to funding, and support organizations working to create meaningful social change.


