
Using an NLP Q&A System To Study Climate Hazards and Nature-Based Solutions
December 19, 2020

How to create a powerful NLP Q&A system in 8 weeks, that resolves queries on a domain-specific knowledge base?

The above snapshot is a classic example of how our NLP Q&A system works. Users can ask questions pertaining to climate hazards (or their solutions) and the model will carve out relevant answers from the collected Knowledge Base.
The model suggests ‘Mangrove forests’, ‘improved river-flow regulation’, and ‘stone bunds’ to tackle floods.
What’s more? We also pinpoint the context that was used to generate the answer along with a hyperlink for those who want to go into more depth (panaroma.solutions in this case).
Let’s explore why we built this system in the first place ?
Why Q&A Systems for Nature-based Solutions?
World Resources Institute (WRI) seeks to understand how nature-based solutions (NbS) like forest and landscape restoration can minimize the impacts of climate change on local communities.
Nature-based Solutions (NbS) are a powerful ally to address societal challenges, such as climate change, biodiversity loss, and food security. As the world strives to emerge from the current pandemic and move towards the UN Sustainable Development Goals, it is imperative that future investments in nature reach their potential by contributing to the health and well-being of people and the planet.
There is a growing interest from governments, business, and civil society in the use of nature for simultaneous benefits to biodiversity and human well-being.
The websites of the initiatives that advocate for NbS are full of information like annual reports, climate risks of the region, impact in the region, how the adaptations are helping in mitigating climate effects, challenges faced, local factors, socio-economic conditions, employment, investment opportunities, government policies, community involvement, inter-platform efforts, etc, which takes a lot of manual effort for studying. The QnA system helps to ease this effort in getting the preliminary information on the focus areas and the reader can then go to specific documents that have relevant answers.
Thus, our system is not a replacement for the human study or analysis, but a tool that highlights the focal points of key information by giving quick and relevant answers from the curated Knowledge Base.
The tool shall provide Climate Adaptation researchers an ability to search a massive quantity of textual information and analyze the impact of NbS on society, ecosystems. Broadly, it answers questions such as
- How are regional/global platforms addressing climate change impacts?
- What is the current state of landscapes, barriers, and opportunities?
- When and how are the NbS being implemented and in which regions?
But, how did we do it? Let us deep-dive into the details of our project.
Data Collection and Preprocessing
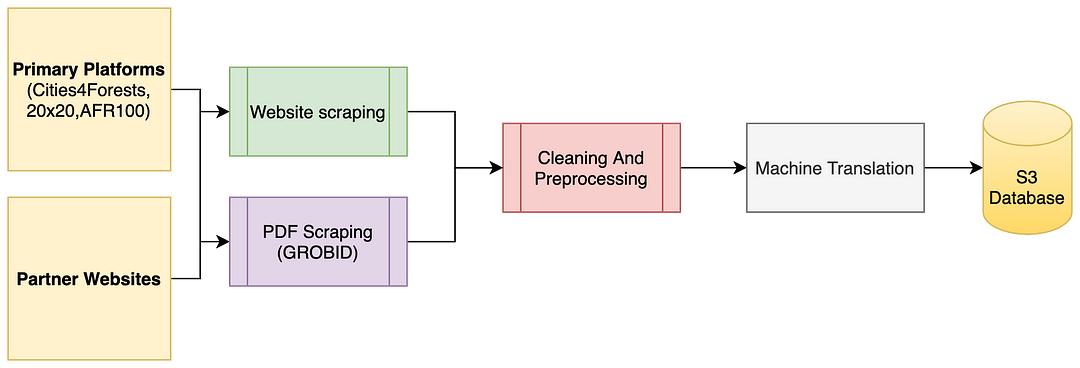
Data Sourcing Pipeline (omdena.com)
The focus of this project was to study the following Coalitions that bring together organizations to promote forest and landscape restoration, enhancing human well-being:
• AFR100 (the African Forest Landscape Restoration Initiative to place 100 million hectares of land into restoration by 2030)
• Initiative 20×20 (the Latin American and Carribean initiative to protect and restore 50 million hectares of land by 2030)
• Cities4Forests (leading cities partnering to combat climate change, protect watersheds and biodiversity, and improve human well-being)
In this article, we shall focus on the PDF text scraping pipeline and SOTA Knowledge-Based Question Answers system.
Deep-dive into PDF text scraping
The websites on our radar have a good number of PDF documents that contain a plethora of information like annual reports, case studies, and research (insights) which is useful to policymakers and domain experts to understand the latest trends across the world. This text extraction process is automated by using GROBID.
GROBID (or GeneRation Of BIbliographic Data) is a machine learning library for extracting, parsing, and re-structuring raw documents such as PDF into structured XML/TEI encoded documents with a particular focus on technical and scientific publications. TIE XML is the industry standard for document content without presentation part. We downloaded and ran the open-source server on our local system. In a complete PDF processing, GROBID manages 55 final labels used to build relatively fine-grained structures, from traditional publication metadata (title, author names, affiliation types, detailed address, journal, volume, issue, etc.) to full-text structures (section title, paragraph, reference markers, head/foot notes, figure headers, etc.)
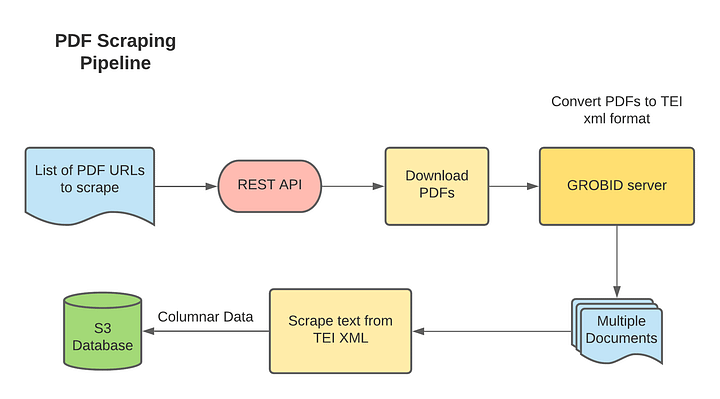
PDF Scraping Pipeline (omdena.com)
The steps are as follows:
- The pipeline takes a list of PDF URLs and generates a consolidated CSV file containing paragraph text from all the PDF documents along with metadata such as the Source system, the download link to PDF, Title of paragraphs, etc.
- All the PDF documents in the three platform websites and some documents which have generic information on nature-based solutions are included
- The documents provided are then converted to TIE XML format using GROBID service.
- These TIE XML documents are further scraped for headers and paragraphs using python’s Beautiful Soup parser.
This utility replaces the manual effort of extracting paragraph text from PDF documents which can be used for further analysis by downstream NLP models.
A Knowledge-Based Question Answering System
The knowledge-based Question & Answering (KQnA) NLP system aims to answers the questions in the domain context on the text scraped data from PDF publications and Partner websites.
The KQnA system is based on Facebook’s Dense Passage Retrieval (DPR) method. Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. DPR embeddings are learned from a small number of questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets, dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage retrieval accuracy.
Retrieval-Augmented Generation (RAG) model combines the powers of pre-trained dense retrieval (DPR) and sequence-to-sequence models. RAG model retrieves documents, passes them to a seq2seq model, then marginalizes them to generate outputs. The retriever and seq2seq modules are initialized from pre-trained models, and fine-tuned jointly, allowing both retrieval and generation to adapt to downstream tasks. It is based on the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
Building the above system from scratch has its own set of challenges as the process is time-consuming and prone to bugs. Hence, we utilized an open-source framework called haystack provided by deepset.ai for our QnA pipeline. Let us go through our custom model pipeline in detail.
System Design
The model is powered by a Retriever-Reader pipeline in order to optimize for both speed and accuracy.

Ingestion Pipeline
Elastic Search on VM was used as a Document store for the storage of documents. The PDF and Website text are stored on two different indices on Elastic search to run on-demand queries on the two streams separately. Filters of Elastic search can be applied on the platform/Url for the focussed search on a particular platform or website. Elastic search 7.6.2 was installed on VM which is compatible with Haystack (as of December 2020).
Inference Pipeline
Readers are powerful models that do a close analysis of documents and perform the core task of question answering.
We used the FARM Reader, which makes Transfer Learning with BERT & Co simple, fast, and enterprise-ready. It’s built upon transformers and provides additional features to simplify the life of developers: Parallelized preprocessing, highly modular design, multi-task learning, experiment tracking, easy debugging, and close integration with AWS SageMaker. With FARM you can build fast proofs-of-concept for tasks like text classification, NER, or question answering and transfer them easily into production.
The Retriever assists the Reader by acting as a lightweight filter that reduces the number of documents that the Reader has to process. It does this by:
- Scanning through all documents in the database
- Quickly identifying the relevant and dismissing the irrelevant
- Passing on only a small candidate set of documents to the Reader
RAG is applied to the generated answers to get a specific answer.
The complete pipeline is as follows:
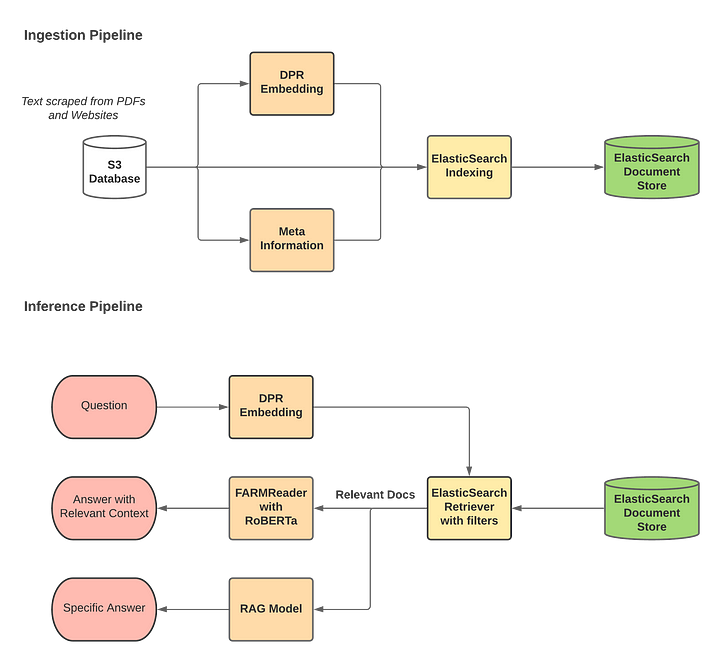
Q&A system Design (omdena.com)
Results
The model is hosted on Omdena AWS server and exposed via a REST API. We used Streamlit to produce a fast and scalable dashboard.
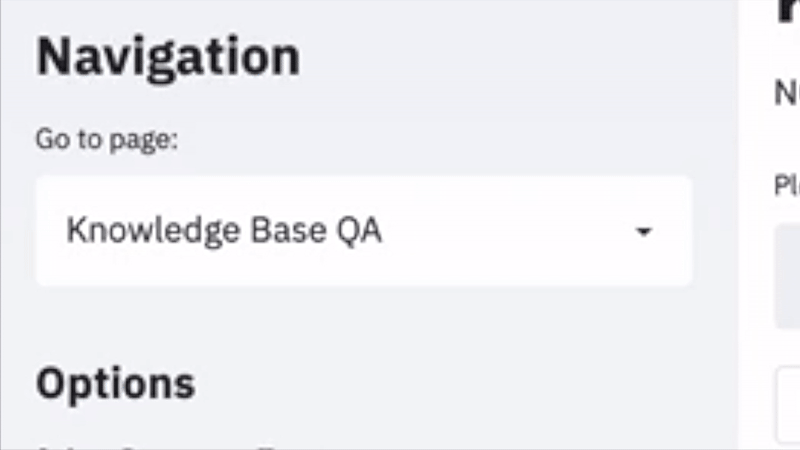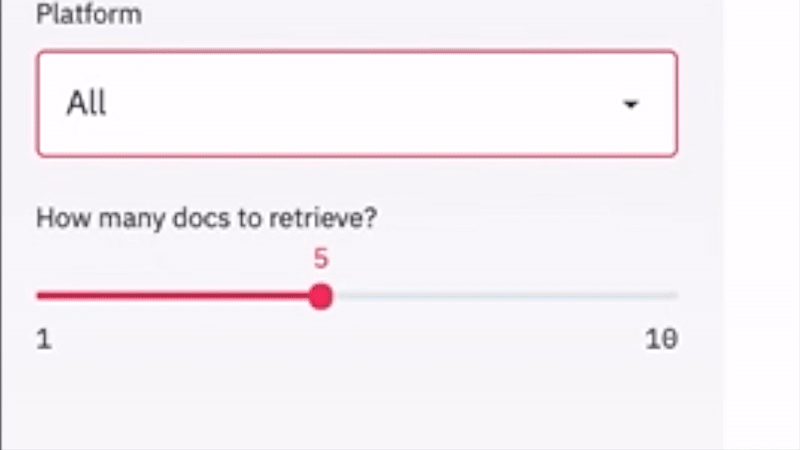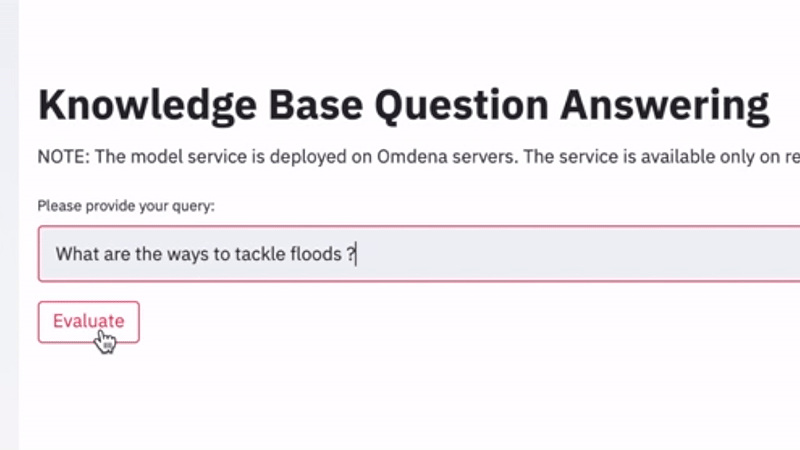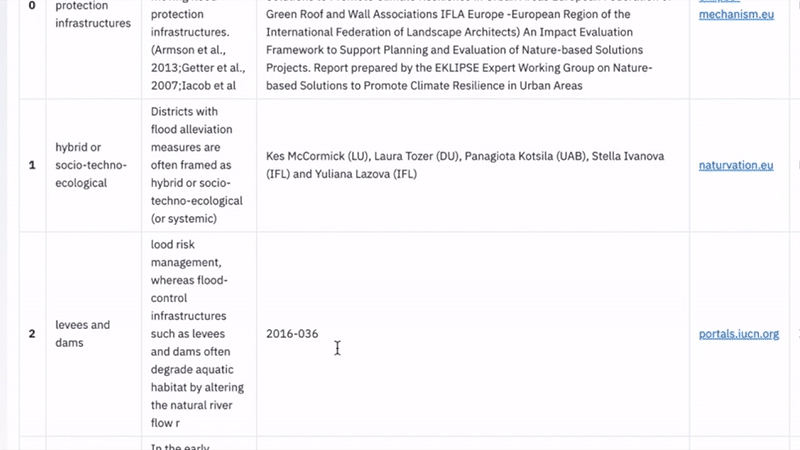
KQnA System Live Demo (omdena.com)
We started this article with an example question around floods but the target search was on a website (panaroma.solutions). The above animation presents a similar question, but this time, the search is performed on PDFs. We get an answer “moving flood protection infrastructures” and “levees and dams”.
A more refined search such as “What is the best way to tackle floods?” returns the following:
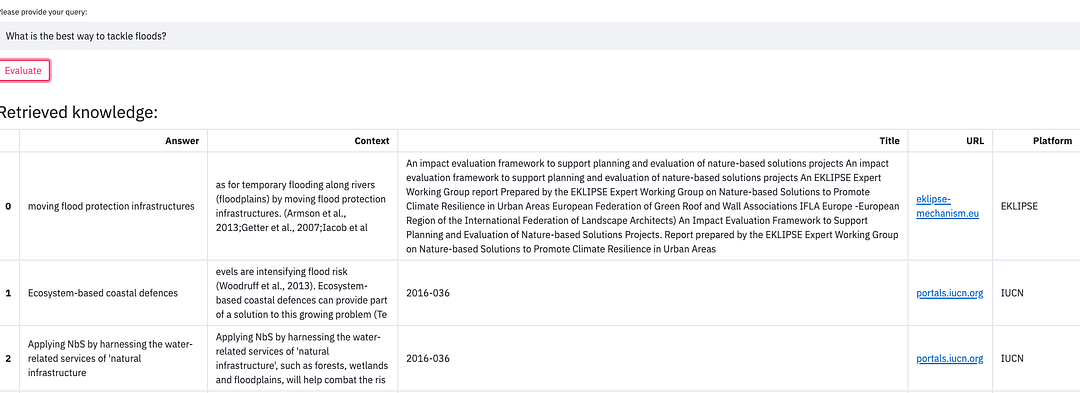
We observe that the system does not answer “levees and dams” since those are not nature-based solutions. Instead, we get documents that talk about ‘ecosystem-based coastal defenses’
Let us look at a few more examples:
“What is the impact of NbS ?” — search all websites
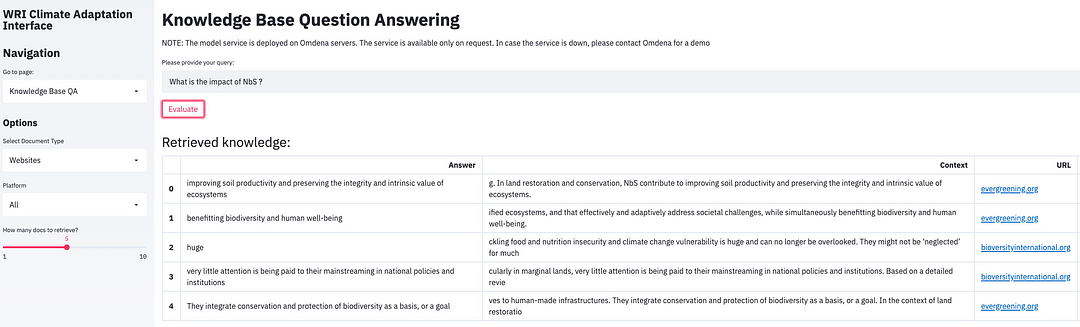
What is the impact of NbS? (omdena.com)
“What is the impact of NbS ?” — search on climatefocus.com
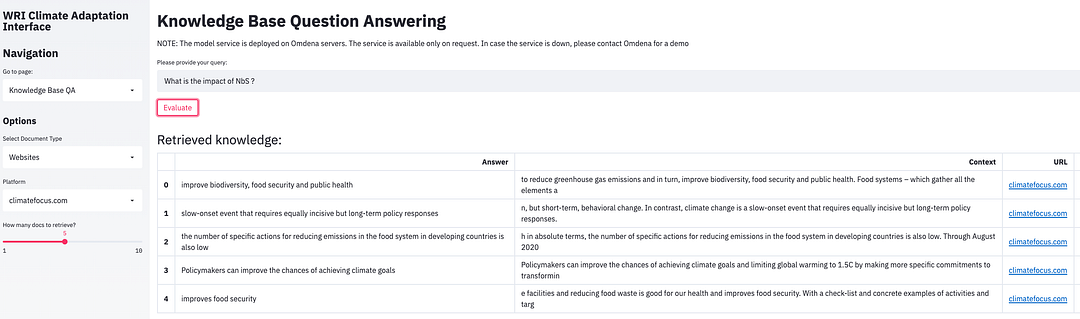
Here, we can understand the general notion around NbS and compare that to content from specific websites such as climatefocus.com. It allows us to contrast the work being done by different websites and how they approach the “NbS”. (In comparison to the earlier query for all websites, now it is run for a single website)
NOTE: The questions posted above are just samples and do not directly indicate an outcome from the Omdena project. The work is a Proof-Of-Concept and requires fine-tuning and analysis by domain experts before productionizing the system.
Conclusion
The KQnA system is found to give pertinent answers to the questions based on context. Its performance is dependent on two factors:
- The quality of the data ingested
- The framing of the question ( It may require a few attempts to ask the question in the right way in order to get the answer you are looking for)
The system can be enhanced by adding more data from PDF documents and websites to the database. Further, if a labeled dataset for climate change is available in the future, then the model can be fine-tuned so that it can better predict the documents and extract the right answers from the database in the context of Climate Change and/or Nature-Based Solutions.
References
- IUCN Nature-based Solutions: https://www.iucn.org/theme/nature-based-solutions
- Haystack: https://github.com/deepset-ai/haystack
- RAG: https://huggingface.co/transformers/model_doc/rag.html
- DPR: https://huggingface.co/transformers/model_doc/dpr.html
- Streamlit Dashboard:https://blog.streamlit.io/
This article is written by Aruna Sri T., Tanmay Laud.



