NLP Pipeline: Understanding Land Ownership in Kenya through Network Analysis
11 min readUpdated November 8, 2024
Omdena
An end-to-end NLP pipeline from collecting and preparing more than 32.000 notices, legal entities, and court documents to build a web-based dashboard displaying land ownership in Kenya. The purpose of this project is to boost Kenya’s efforts to restore degraded land in an equitable way.
Monitoring global environmental change relies both on detecting measurable biophysical changes as well as social changes, such as new policies, changes in governments, grassroots movements, or social barriers to sustainability.
However, the identification of hidden actors and interests behind land management has been a real challenge. This has limited the development of clear action plans to ensure good land governance and prevent land corruption, conflict, injustices, and inequalities.
‘Land is a “key fault line”1 in Kenya. Throughout East Africa, land reform has failed to confront the material consequences of unequal access.’ from Africaresearchinstitute.org
That is exactly what we were trying to tackle in this project. Omdena, partnering with World Resources Institute (WRI), Code for Africa, and Stanford University joined forces to make the most of AI, graph-based analytics, and natural language processing (NLP) to understand land ownership as well as corporation and legal entities’ networks and subnetworks involved in land transfers.
‘In Kenya, the land problem is one of the main issues that citizens have reported and sought legal advice on through the Advocacy and Legal Advisory Centres (ALACs)’ from ADILI Institute.
Data acquisition
One of the main challenges of the project was to create a scalable NLP pipeline for continuous data ingestion into our defined ML workflow (see below). So, the first question to ask was…which publicly available datasets, resources, or public archives of records/leaks could help us to support investigative data journalism and evidence-based actions against corruption? Moreover, which one is the ‘right’ one?
ML pipeline as a reference for land ownership with NLP task-based workflow – Source: Omdena
We evaluated diverse data sources available in a series of initiatives under the connectedAFRICA project: including the sourceAFRICA repository, the gazeti.AFRICA digitization campaign and the connectedAFRICA itself.
All these data sources gave us access to a bunch of interesting courts/legal, political/electoral, government/public, and company documents, including whistleblower and investigative media evidence.
After an exploratory data analysis (EDA) over some potential data sources and based on different criteria (e.g, temporal coverage, number of documents available, updating patterns, information and possible entities of interest contained); we decided to take 3 datasets to work over:
Keny Gazettes: an official publication of the government of the Republic of Kenya that publishes the following: Notices of new legislation Notices required to be published by law or policy Announcements for general public information. Size: ~183K documents
Kenya Court Cases: Kenya court case rulings published by The National Council for Law Reporting. Size: ~6K documents.
Kenya NEMA EIA Reports: Environmental Impact Assessment Reports from the National Environment Management Authority, Kenya. Size: ~1.5K documents.
These 3 datasets were available as unstructured data (mainly scanned PDFs). We, therefore, built a data ingestion pipeline (see OCR data pipeline below) for sampling data (download), filter them (based on ‘land related’ and DateTime range) as well as enable information extraction based on OCR-ed documents.
Scalable OCR data pipeline – Source: Omdena
Benchmarking SOTA OCR tools, our search for the ‘best’ OCR tool
In our effort to use an efficient Optical Character Recognition (OCR) tool for all datasets, we benchmarked different OCR services/tools. The benchmark criteria were both qualitative (the quality of textual representations) and quantitative (performance, cost, and scalability)
Benchmark criteria for current SOTA OCR tools – Source: Omdena
Experimental research on the following OCR tools:
Apache SparkOCR: commercial extension of Spark NLP (library) for optical character recognition from images, scanned PDF documents, and DICOM files. Claimed F1-score: 0 .9812
AWSTextract: a fully managed machine learning service that automatically extracts printed text, handwriting, and other data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Claimed F1-score: 0.93
Azure Cognitive Services Optical Character Recognition (OCR): API including Optical Character Recognition (OCR) capabilities that extract printed or handwritten text from images. Able to extract text from images, such as photos of license plates or containers with serial numbers, as well as from documents — invoices, bills, financial reports, articles, and more.
From Azure, we did not only cover Read API, but we also evaluated Form Recognizer API for tackling the challenging tables and graphical identification.
Tesseract (pytesseract): a wrapper for Tesseract-OCR Engine.Tesseract 4 adds a new neural net (LSTM) based OCR engine which is focused on line recognition but keeping the legacy Tesseract OCR engine by recognizing character patterns.
We identified some strong weaknesses on Tesseract at the first stages of the project: the main one was the inability to deal with different columns under the same gazette and thus, not finding a way to separate different land notices. The lack of a meaningful automation way to separate different land-related notices across each gazette leads us to explore new commercial solutions.
Among all of them, transformers-based SparkOCR boosted the data quality assessment we performed and we decided to mainly rely on this one as the backbone for our information extraction process. Also, SparkOCR seemed to scale-out naturally on different workers.
All of our potential data sources were sampled (on a pseudo-random basis), although only documents from Kenya Gazettes and Court Archives were OCRed and ‘pushed’ into the next stage of our ML workflow: Semantic manual annotation.
Which market annotation tool suits our NER problem?
We carried out a similar approach for Annotation Tools. We selected the following tools for further analysis:
Brat: an online environment for collaborative text annotation.
Doccano: a well-established open-source annotation tool for text classification, sequence labeling, and sequence to sequence tasks.
Inception: a semantic annotation platform offering intelligent annotation assistance and knowledge management.
All of them were evaluated on both functional, technical and active community support and acceptance criteria.
On the functional side, we were ranking the tools based on our main needs: support for multiple layers (chunk, coreference, dependency. lemma, named entity, morphological features…), relationships support, team annotation support, data privacy, pre-annotations, and active learning, and of course KB support. Another interesting functional feature to be explored is inter-annotator agreement (IAA) which we were not able to completely exploit due to limited resources.
On the technical side, we focused mainly on the usability of the tool, easiness of installation, license type (open source), quality of the documentation, and intuitiveness of the UI on the annotation process.
Advanced features on Inception platform: Machine-Assisted and Knowledge-Oriented Interactive Annotation
The context of our project was based on Aleph project investigative tools, so our initial main goal was to be able to be Aleph (Follow the Money) compliant and thus, being able to annotate ‘on top’ on some ontologies, taxonomies, or reusing Aleph terminology and schema was crucial.
FTM ontology: Things (or nodes) include People, Companies, Documents, and similar entity types. From https://docs.alephdata.org/FTM ontology: Intervals are temporary in nature, and often define a relationship between two or more things, e.g. a membership in an organization, or a family association
This unique feature was determinant on going ahead into Inception, providing us the opportunity to link different concepts, entities, and facts and support the annotation on standard vocabularies.
Human-in-the-Loop Data Labeling (HITL)
During the whole data labeling process, the team tried to make the most of the available functional features to make annotation as well as model development faster and more cost-efficient.
For that, we exploited the Active Learning (AL) feature and recommenders from Inception to speed up and improve the accuracy of the annotation process. Recommenders learn from what the user annotates and automatically suggest annotations.
We worked on a single project configuration with different possible roles for each collaborator (admin, annotator, reviewer) and created some annotation guidelines on top of this project for each dataset. We decided to work in a distributed fashion for process simplification and easy coordination.
Gazette named-entity layer annotation example based on custom tagsets
Modeling under legal/law domain: a named entity recognition approach
Our modeling process has been mainly guided by the legal entities, assets, and court cases that were susceptible to help us correlating both Gazettes land notices and Court Archives (and of course, future enriching datasets).
List of entities of interest on Land related Gazettes (tagset)
The cross-reference across all datasets turned out crucial for our insights and investigative reports involving diverse legal entities and relationships between them (such as Family relations, or business interests — ownership as in case of land assets, or even some links like sanctions, payments, or illegal transfers).
Cross-referencing across datasets. Additional discriminative features like location or personal details when available to reduce the uncertaintySample of Land gazette entities on displaCy
For entities identification, we carried out NLP based named entity recognition (NER task), benchmarking different general-purpose and domain-specific models, concretely:
Spacy NER trained on customed tags.
BERT, LEGAR-BERT-BASE (see evaluated domain-specific models below).
Attention-based LSTM model.
Domain-specific models. Models available on https://hugginface.co/
As a result of the benchmark, Spacy NER outperformed with an overall 0.95 precision and 0.97 recall. From metrics at the entity level (per type), the lowest-performing entities were owners_name, signators_name, and land_identification_number. We had to face some challenges in evaluating and mitigating missing values for pushing the results into the next workflow stage (KG creation).
This ‘lack of information’ was especially challenging for geolocating land assets involved in transactions as well as owners.
Graph-powered investigative journalism!
The inspector use cases under the scope of the project, inherently called for a knowledge graph (KG) construction, able to not only identify third party entities involved in different court cases, land assets, and companies… but also to flag some ‘suspicious’ facts on land transactions and vast ownership. Also, the underlying interest in understanding intricate and potentially complex networks of people, companies, and transactions on land ownership has been a clear sign to exploit some graph analytics on top of our persisted KG.
Thus, we decided to store and analyze the network in a graph native database that could help us to gain critical insights into the complex relationships between different legal entities (nodes). From the available commercial graph native storage databases, Neo4J was selected to exploit both transactional capabilities as well as a native graph processing engine.
From https://docs.alephdata.org. Exporting data into a graph network
Project Outcomes
We are extremely proud of tangible achievements under this project. The hard-working team lead us to contribute and cover most of the use cases and expectations by the consortium members such as land use and mining concessions, legal entanglement ‘flagging’ ownership/concessions of entities involved in legal proceedings (court records) as well as characterization of the ownership distribution based on some interesting factors like gender, ethnic, country and in more fine granular districts within a country (Kenya).
“Some figures around the project…>32K notices were inspected within a time range of 2010-2020. >400 court documents…. 34649 legal entities inspected!”
The main artifacts resulted from the project were:
The core deliverable of the project, a Knowledge Graph persisted on a Neo4j labeled property graph representing different entities (nodes) and relationships (edges) identified on land-related legal documents and possible networks and subnetworks that arises from them.
‘Watchlist’ resulted from more than 34K inspected entities. This represents a list of legal entities based on some identified ‘red flags’ like abnormality on ownership size or legal entanglement. A suspicious score was calculated based on Wordnet cognitive synsets occurrences on court case facts. This has been introduced into the land ownership dashboard.
Land Ownership Dashboard for decision support in inspector journalism as well as land-related policy-making.
Visual analytics for tracking district-based ownership in Kenya – Source: Omdena
Geolocated resources for land use tracking.
Baseline and tech stack (Graph Data Science on Neo4j) for further graph-based analysis on network topology and network metrics such as network centrality and influence measures of entities, community detection (clusters of entities/companies identified on legal documents), similarity or network evolution analysis and link prediction based on well-known models like Preferential Attachment or Small World Network.
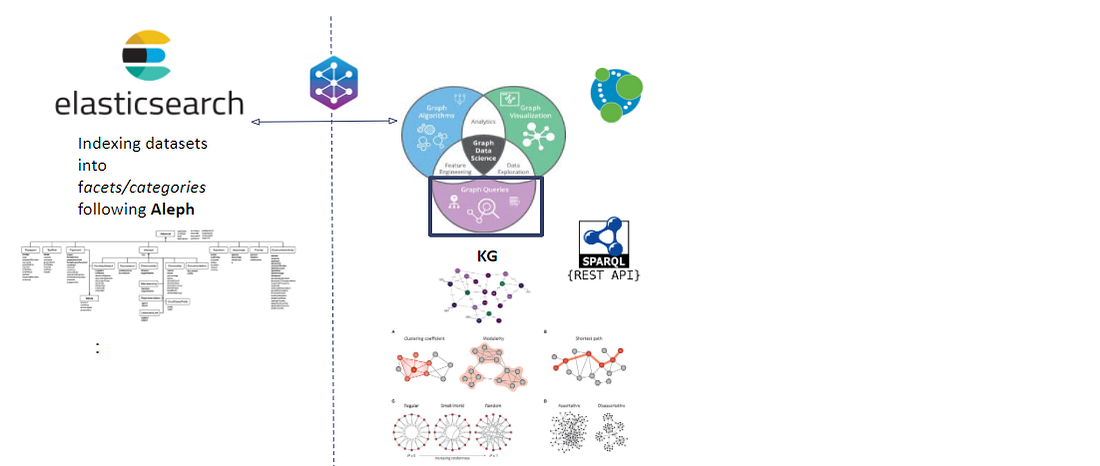
Graph-powered Search under Aleph. Integrating POC into the current architecture
Opportunity Just Ahead
We identified 4 main axes for improvement opportunities: Aleph compliance, NER pipeline improvement, data pipeline (scaling to new data sources), and currently available search as well as inspection capabilities.
Enriching current entities with publicly available data sources. From ‘A Preliminary Study on Wikipedia, DBpedia and Wikidata’Data Enrichment on politically exposed people (PEP) list and LinkedData
It has been a great journey, thanks to the great project team and Omdena for this amazing opportunity!!!
This article is written by Irune Lansorena and Francis Onyango.






{kind=link}
{kind=link}
{kind=link}
{kind=link}