
Best Topic Modeling Python Libraries Compared (+ Top NLP Projects)
10 best topic modeling libraries in Python that you can use to analyze large collections of documents for identifying key topics.


Introduction
You can extract desired topics from large volumes of text using the applications of Natural Language Processing (NLP). The large text can include customer reviews of movies, restaurants, etc., feeds from social media, emails of customer complaints, user feedback, and so on.
It is essential to know what people are talking about because their opinions and the problems they face can significantly affect businesses on a large scale. But how can one manually read through large data chunks and compile the topics?
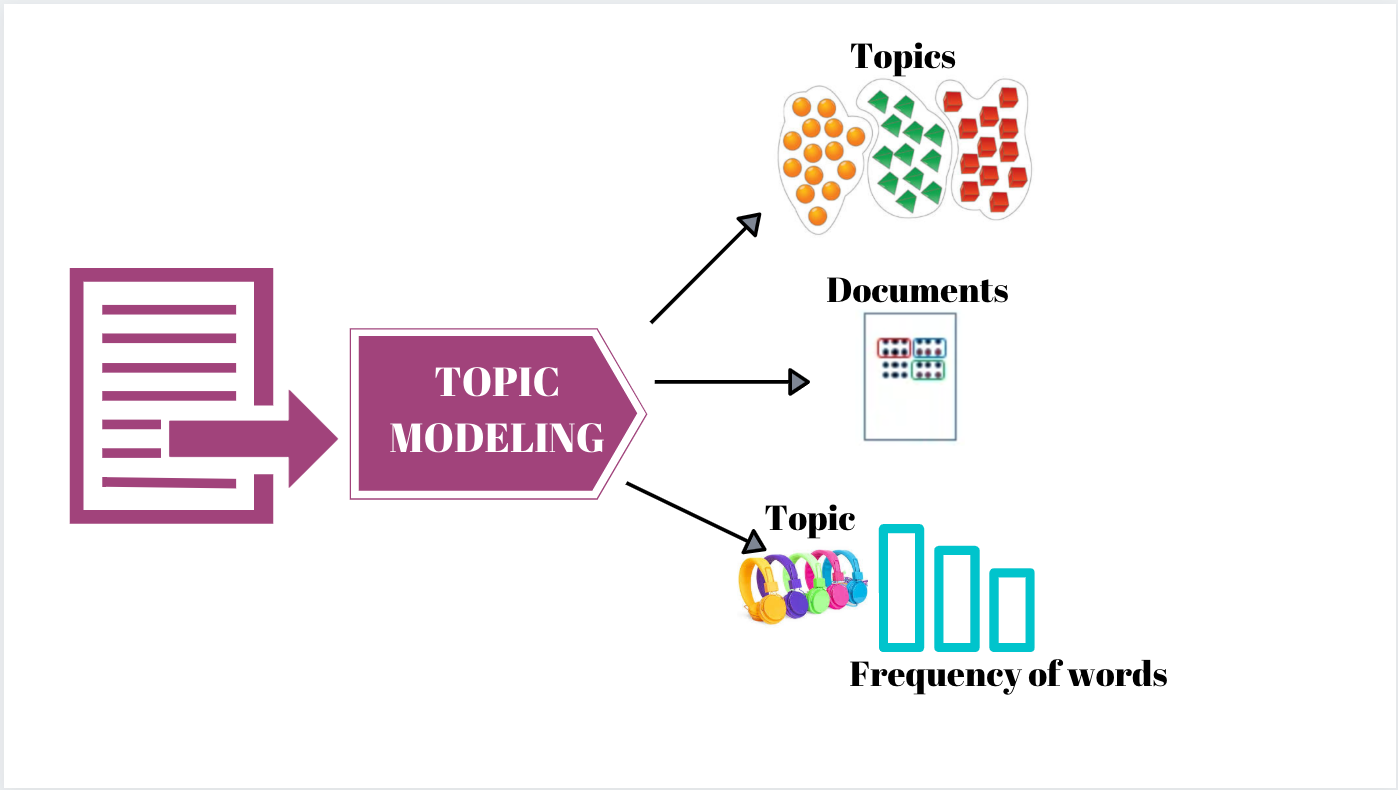
Here comes the need for an automated technique called “Topic Modeling” that can read through the voluminous data and output the relevant topics. Let’s dive into the details of Topic Modeling and its techniques in NLP.
What is Topic Modeling?
Topic modeling is a statistical model that extracts the hidden topics from large volumes of text by assigning categories or tags according to each individual’s theme/topic. It clusters similar expressions and infers patterns without defining the topic tags beforehand. Other names for Topic Modeling are Topic Detection, Topic Extraction, and Topic Analysis.
Topic Modeling uses Natural Language Processing to break down the human language. This way, you can unlock semantic structures and find patterns within texts to extract valuable information and make data-driven decisions.
You can apply topic modeling at three different scope levels as defined below.
- Subsentence-level – The topic model in the sub-sentence domain infers the topic of sub-expressions and components from within a sentence. For instance, there can be different topics within a single sentence of customer feedback.
- Sentence-level – The topic model in the sentence domain infers the topic of a single sentence. For instance, the newspaper headline can have a single topic.
- Document-level – The topic model in the document domain infers different topics from within a complete text. For instance, an email or a news article can have a variety of topics.
Topic Modeling in NLP
It is a time-consuming, expensive, and inaccurate technique to find topics within a text manually. Topic Modeling analyzes large volumes of text data cost-effectively. You can use it for the following purposes.
- Automating business processes
- Getting valuable insights from data
- Making your teams more efficient
- Saving hours of manual data processing
You can analyze a large dataset of reviews and find out what people say about your product. To do this, you can use sentiment analysis with topic modeling and discover which features and aspects of your product are frequently discussed. You can also find out how people feel about your product and whether their feedback is positive, negative, or neutral. This method is called aspect-based sentiment analysis.

You can also use Natural Language Processing techniques such as topic modeling in the following areas:
- Customer Service
- Social Media Monitoring
- Sales and Marketing
- Search Engine Optimization
- Voice of Customer Analysis
- Knowledge Management
- Product Analytics etc.
Some benefits of using topic modeling in Natural Language Processing are given below.
- Accurate Results – Automated topic modeling is a Natural Language Processing technique that combines computer science, statistics, and computational linguistics. Therefore, you can expect high-quality and accurate results using this technique.
- Real-time Analysis – We can obtain a real-time picture of what our clients say about our product by combining topic modeling with other NLP techniques such as sentiment analysis. Further, we can use the information to make real-time data-driven decisions.
- Data Analysis at large scale – It is time-consuming and expensive to manually detect topics in a vast database. Therefore, we can use automated topic modeling with machine learning to scan as much data as we want and obtain meaningful insights.
Topic Modeling Techniques

Below are some topic modeling techniques that we can use to understand the complex content of the documents.
- Latent Dirichlet Allocation (LDA)
- Latent Semantic Analysis (LSA)
- Parallel Latent Dirichlet Allocation (PLDA)
- Non Negative Matrix Factorization (NMF)
- Pachinko Allocation Model (PAM)
Let’s briefly discuss each of the topic modeling techniques.
Latent Dirichlet Allocation (LDA)
It is a statistical and graphical model that obtains relationships between multiple documents in a corpus. It can also be used to determine the maximum likelihood estimate from the whole text corpus as it is developed using Variational Exception Maximization (VEM) algorithm.
The fundamental assumption here is that:
We can describe each document by the probabilistic distribution of topics. Likewise, each topic can be described by the probabilistic distribution of words. Also, the documents with the same topic can use similar words. This assumption helps us better understand how the topics are connected.
Suppose you have a corpus of a thousand documents. After preprocessing the corpus, the bag of words consists of a thousand common words. By using Latent Dirichlet Allocation, we can find the topics related to each document. This way, it will be easier for us to obtain meaningful insights from data.
Latent Semantic Analysis (LSA)
It is also an unsupervised machine learning technique that determines relationships between different words in a pile of documents. This way, it helps us in choosing the correct documents required.
Latent Semantic Analysis is based on a principle termed as distributional hypothesis, which states that:
Words and expressions occurring in similar pieces of text will have similar meanings.
The irrelevant data in a text corpus acts as a noise and prevents us from extracting meaningful insights. Latent Semantic Analysis acts as a dimensionality reduction method, reducing the dimensions of a massive corpus of text data and eliminating noise.
Parallel Latent Dirichlet Allocation (PLDA)
This technique is also known as Partially Labeled Dirichlet Allocation. It assumes that:
In a set of n labels, each label is associated with the topics of a given corpus.
Also, we can represent individual topics as the probabilistic distribution of the whole corpus (similar to LDA).
Parallel Latent Dirichlet Allocation also assumes that only one label exists for each theme/topic in the text corpus.
Non Negative Matrix Factorization (NMF)
It is a matrix factorization method that uses non-negative elements in factorized matrices. Suppose you obtain the document-term matrix from a text corpus after removing the stopwords. You can factorize the matrices into the following two matrices.
- Term-topic matrix
- Topic-document matrix
You can use many optimization models to perform the matrix factorization. For instance, you can use the Hierarchical Alternating Least Square algorithm to perform NMF better.
Pachinko Allocation Model
It is an improved version of the Latent Dirichlet Allocation model. We know that LDA identifies topics and brings out the correlation between words in a text corpus. On the other hand, the Pachinko Allocation model improvises by establishing a correlation between the generated topics.
PAM has greater power to determine the semantic relationship precisely as it brings out the correlation between topics rather than words.
10 Best Python Topic Modeling Libraries

Below are the ten best topic modeling libraries in Python that you can use to analyze large collections of documents for identifying key topics.
Gensim
Gensim is an open-source Python library that represents documents as semantic vectors. It processes unstructured, raw digital texts using unsupervised machine learning algorithms.
Some popular features of gensim are as:
- It is the fastest library to train vector embeddings.
- Gensim runs on all platforms that support Python and Numpy, such as Windows, Linux, etc.
- The core algorithms in gensim are highly optimized and memory-independent with respect to the corpus size.
MUSE
MUSE stands for Multilingual Unsupervised and Supervised Embeddings. It is a Python library meant for multilingual word embeddings and provides the community with the following features
- High-quality bilingual dictionaries for training and evaluation
- State-of-the-art multilingual word embeddings based on fastText
Other features that MUSE library provides to the community are:
- Getting evaluation datasets
- Aligning monolingual word embeddings
- Evaluating monolingual or cross-lingual embeddings
Texthero
Texthero is a Python package that you can use to work with text data efficiently. Some essential features of Texthero are as follows:
- It provides a solid pipeline for cleaning and representing text data.
- It empowers the NLP developers with a tool that helps them quickly understand the text-based dataset.
BERTopic
It is a topic modeling library in Python that creates dense clusters using BERT embeddings (transformers) and class-based TF-IDF. The class-based TF-IDF supplies all documents of a single class with the same class vector.
BERTopic supports supervised, semi-supervised, and dynamic topic modeling.
Scattertext
It is an open-source Python library that you can use to create beautiful visualizations of words and phrases of a given category.
You can also use Scattertext to find distinctive patterns in text corpora and present them in an interactive scatter plot with non-overlapping term labels.
LDA
It is a Python library that implements Latent Dirichlet Allocation (LDA) using collapsed Gibbs sampling.
It aims for simplicity and is fast. It is tested on Windows, Linux, and OS X.
GuidedLDA
GuidedLDA is a Python library that allows users to pre-define priors (topics) with keywords to perform theory-driven textual data analysis.
GuidedLDA is also called SeededLDA. It is a semi-supervised technique.
ETM
Embedded-topic-model is a Python library that models topics as points in the same word embedding space. This library arranges the topics and words together with similar contexts.
We can also give pre-trained embeddings to ETM to discover the topic patterns on the text corpus.
Contextualized-topic-models
It is a Python library that uses pre-trained language representations to support topic modeling.
There are two models in CTMs (having different use cases), namely:
- CombinedTM
- ZeroShotTM
Deep-siamese-text-similarity
It is a Python library that captures the sentence/phrase similarity using character embeddings.
Deep-siamese-text-similarity library is a TensorFlow-based implementation of a deep siamese LSTM network.
Top 5 NLP Projects in 2024

Source
Given below are the top Natural Language Processing projects of 2022:
Lemmatization
It is an NLP project that implements the lemmatizer using Python’s NLTK package and applies it to a resume. It compares the output with the stemmed form of the same resume.
The project uses the following helper classes to create the stemmed, lemmatized, and tokenized output.
- PorterStemmer
- Lemmatizer
- Tokenizer
You can learn more about the project in detail using this link.
ChatBot using NLTK
This project creates a chatbot that answers questions related to machine learning. It uses NLTK (Natural Language Toolkit), which helps build Python programs to work with human language data.
You can learn more about the project in detail using this link.
MedaCy
MedaCy is an abbreviation for Medical Text Mining and Information Extraction with spaCy.This framework is built over spaCy to support the application of highly predictive medical NLP models.
You can learn more about the project in detail using this link.
A BI Tool to Collect Online Financial Information

Source: Omdena
This Omdena project uses end-to-end web scraping and Natural Language Processing techniques to gather financial business information about a given company via keyword extraction and sentiment analysis. It uses Amazon as an example use case for scraping financial news and discovering an organization’s sentiment tone and business events.
You can learn more about the project in detail using this link.
Further, you can also check this project link that addresses unemployment in Nigeria.
Farm Advisory

It is an NLP-based web portal that helps farmers in crop planning and handling. It has the following features.
- It gives information to the farmers on crop handling techniques like soil type requirements, water requirements, etc.
- It recommends crops based on attributes such as location.
- It provides a discussion space for experts and farmers in the related fields.
You can learn more about the project in detail using this link.
Conclusion
So far, we have discussed topic modeling in Natural Language Processing and its use cases. Some of the summarized applications of topic modeling are given below.
- We can use it in graph-based models for obtaining semantic relationships between words.
- We can use topic modeling to recommend products to the customers accordingly by identifying the search keywords.
- We can use topic modeling in exam evaluation to avoid biased attitudes towards candidates.
You might also like



{kind=link}
{kind=link}