
An Attempt to Identify Cybersex Crimes through Artificial Intelligence
April 25, 2020

The problem
The vast growth in technology and social media has revolutionized our lives by transforming the way we connect and communicate. Unfortunately, the darker side of this development has exposed a lot of children and teenagers from various ages to become victims of online sexual abuse.
To help combat the severity of the problem, I joined an Omdena project together with the Zero Abuse Project. Among 45 Omdena collaborators from across 6 continents, the goal was to build AI models to identify patterns in the behavior of institutions when they cover-up incidents of sexual abuse.
The identification and analysis of sexual crimes assure public safety and has been made possible by leveraging AI. Natural Language Processing and various machine learning techniques have played a major in the successful identification of online sexual abuse.
The solution
The main idea of this task was to classify online chats between two persons as sexual abuse or non-sexual abuse. We planned in implementing this by using text mining and deep learning techniques such as LSTM-RNN. In the following example, our idea aimed at classifying the chats as predatory or non-predatory.

Classifying online chats
We have used the open-source PAN2012 dataset provided in the context of the Sexual Predator Identification (SPI) Task in 2012 initiated by PAN (Plagiarism analysis, authorship identification, and near-duplicate detection) lab. However, the realistic data provided by PAN has a high noise level with unbalanced training samples and varying length of conversations.
The challenging part of this dataset was in changing the chat text abbreviations and cyber slang texts such as “u” for “you”, “ur” for “your” and “l8r” for “later”. Such words are necessary for feature selection and for improving the performance of the model used for the classification.
Wait, are we stuck with preprocessing?
Initially, with the huge dataset and high noise levels, preprocessing did seem like a herculean task! Well, 80% of the time goes into preprocessing in order to achieve the best results. We managed to implement it by using text mining techniques. We started off by carrying out a basic analysis of checking for null characters, finding the sentence length of each text message as well as finding out the words with the highest frequencies. We also implemented the removal of stopwords, stemming, and lemmatization. The aim of both stemming and lemmatization is to reduce the corpus size and complexity for creating embeddings from simpler words which is useful for sentiment analysis. Stopwords are words that are omitted since it does not provide value for the machine’s understanding of texts.
Furthermore, we realized our dataset contained loads of emojis, URLs, hashtags, misspelled words, and slangs. In order to reduce the noise levels to a greater extent, we had to remove the emoticons from the chats using regular expressions and change the misspelled words by creating a dictionary. The tricky part here involved converting the chat slang abbreviations since it was necessary for feature selection. Unfortunately, it was difficult to find a library or database of words that do that. We had to create a dictionary for that purpose.
slang_dict = {"aren't": "are not", "can't": "cannot", "couldn't": "could not","didn't": "did not","doesn't": "does not",
"don't": "do not","hadn't": "had not"......}
def process_data(data): data['text_clean']=data['text_clean'].str.lower() data['text_clean']=data['text_clean'].astype(str) data.replace(slang_dict,regex=True,inplace=True) display(data.head(2)) return data
The Exploratory Data Analysis
We further tried to analyze the top 20 frequently words in the chatlogs as unigrams and bigrams. A unigram is an n-gram consisting of a single word from a sequence and bigrams contain two words from a sequence.
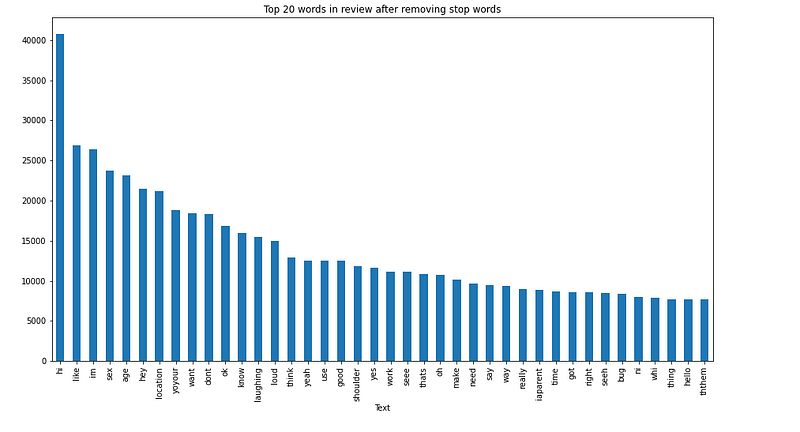
Top 20 Unigrams
From the analysis, we inferred that words such as “age”,” sex”, “hi” etc were very frequently used in the catalogs.
Moving into the language model and classification
The XML dataset provided by PAN2012 is unlabelled and manual labeling is a pretty difficult task considering the number of samples present in the dataset. To solve this situation, sentiment analysis was carried out to identify the polarity and subjectivity of the chatlogs. Polarity is a float which lies in the range of [-1,1] where 1 means positive statement and -1 means a negative statement. Subjective sentences generally refer to personal opinion, emotion, or judgment whereas objective refers to factual information. Subjectivity is also a float which lies in the range of [0,1].
Considering the different number of sentences in conversations (from 1 to more than 500), the extra-long conversations were padded by zeros and then split into parts, each with an equal length of 100. This strategy is helpful to prevent underfitting in the LSTM-RNN model when processing long conversations. These tokenized words were converted into word embeddings to be fed into the LSTM-RNN classifier using the GLoVe pre-trained model.
GloVe stands for global vectors for word representation. It is an unsupervised learning algorithm developed by Stanford for generating word embeddings by aggregating a global word-word co-occurrence matrix from a corpus.
# Co-occurence matrix
def fill_embedding_matrix(tokenizer):
vocab_size = len(tokenizer.word_index)
embedding_matrix = np.zeros((vocab_size+1, 100))
for word, i in tokenizer.word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
return embedding_matrix
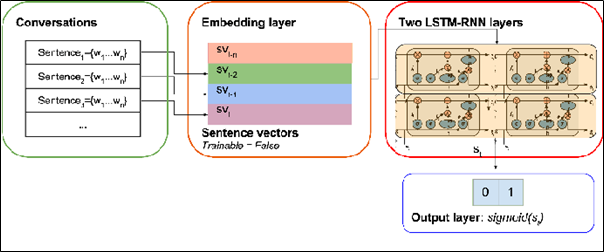
The architecture of the LSTM-RNN classifier
Each word embedding is fed into the binary LSTM-RNN classifier. It consists of one embedding layer, two LSTM-RNN layers with 200 units and 50 timesteps as well as a sigmoid layer that is implemented on the Tensorflow framework for the binary classification. The results could have been improved if labeling the chatlogs could be efficient and if the persisting noise in the dataset could be reduced. However, this task of classifying the sexual predators provided us a clearer perspective of an efficient feature selection and new approaches to solving the labeling problem in order to improve the accuracy of the LSTM-RNN classification.
Sources
[1] https://arxiv.org/ftp/arxiv/papers/1712/1712.03903.pdf
[2] https://pan.webis.de/clef12/pan12-web/sexual-predator-identification.html



