
Neural Transfer Learning in NLP for Post-Traumatic-Stress-Disorder Assessment
May 11, 2020

The Problem Statement
“The challenge is to build a chatbot where a user can answer some questions and the system will guide the person with a number of therapy and advice options.”
We were allocated to the ML modeling team of the challenge. Our initial scope was nailing the problem to the most relevant specific use case. After some iterations and consultations among the team, we decided to tackle among multiple possible avenues (e.g. conversational natural language algorithms, expert system, etc.) the problem with a risk a binary assessment classifier suggestion based on labeled DSM5 criteria. The working hypothesis was that the classifier could be used as a backend of a chatbot in a low resource device that could detect the risk and refer the user to more specialized information or as a screening mechanism (in a refugee camp, in a resource depleted health facility, etc.).
The frontend of the system would be a chatbot ( potentially conversational mixed with open-ended questions) and one of the classifiers would be a risk assessment based on the conversation.
The tool is strictly informational/educational and in no circumstances, the intent is to replace health practitioners.
Our team Psychologist guided the annotation process. After a couple of iterations in the process, we ended up on a streamlined process that allowed us to classify ~50 transcripts (each with the transcripts of conversations).
The Baseline
Baseline algorithm implementation by different team members demonstrated that without further data-preprocessing with traditional ML methods accuracy rate was around 75%. Given the fact that we had a serious category imbalance issue, this is definitely not a metric to consider. An article is in the works with the details of the baseline infrastructure and traditional ML techniques applied to text classification problems ( ).
The Data
The annotation team ended up having access to 1,700 transcripts of sessions. After careful inspection, the team realized that only around 48 transcripts were for actual PTSD issues.
Training Examples: #48 PTSD transcripts each with an average of 2k+ lines
Example of an excerpt of a transcript available in [3]:

Target Definition: No-Risk Detected-> 0 or Risk Detected: 1
From an NLP/ML problem taxonomy perspective, the number of datasets is extremely limited. So this problem would be classified as a few shots of classification problems [4].
Prior art on using these techniques when the data is limited prompted the team to explore the Transfer Learning avenue in NLP with recent encouraging results in a few shots training and data augmentation through back-translation techniques.
The picture below elucidates a pandas data frame resulted in an intense data munging process and target calculations ( based on DSM5 manual recommendations) and the amazing work of our annotation team:
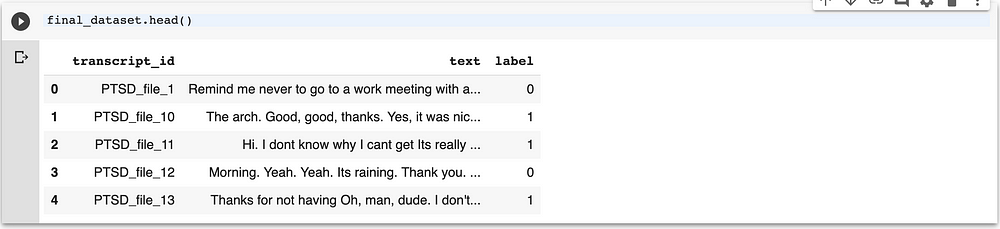
The Solution
ULMFIT
The ULMFit algorithm was one of the initial techniques to provide effective neural transfer learning with success for the state of the art NLP benchmarks[1]
The algorithm and the paper introduce a myriad of techniques to improve the efficiency of RNNs training. We will delve below in the most fundamental ones.
The pre-assumption on modern transfer learning in NLP problems is that all the inputs of all the text will be transformed in numeric values based on word embeddings[8]. In that way, we ensure semantic representation and at the same time numeric inputs to feed the neural network architecture at hand.
From a context perspective. Traditional ML relies solely on the data that you have for the learning task while Transfer Learning trains on top of weights of neural networks (NLP) pre-trained on a large corpus (examples: Wikipedia, public domain books). Successes for transfer learning in NLP and Computer Vision are widespread in the last decade.
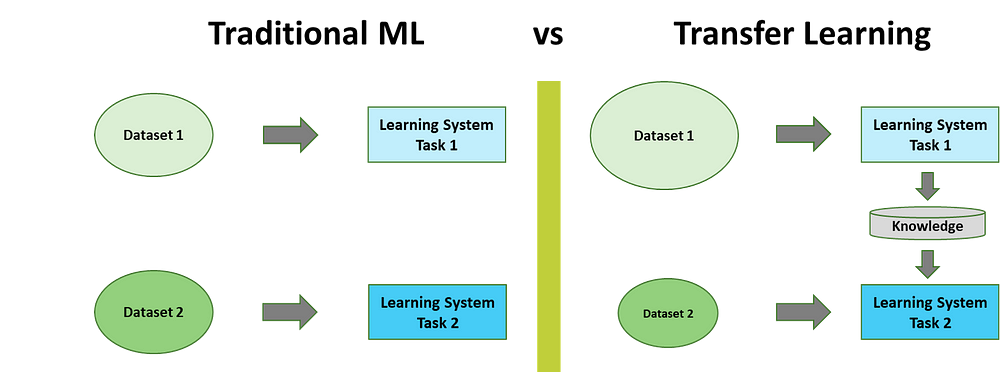
Copied from [5]
Transfer learning is a good candidate when you have few training examples and can leverage existing pre-trained powerful networks.
UMLFit works as shown by the diagram below:
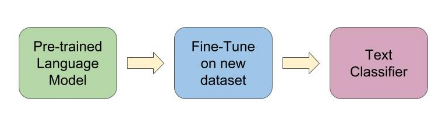
Copied from [5]
- Pre-trained Language Model (for example with Wikipedia data)
- Data is fine-tuned with your corpus (not annotated)
- A classifier layer is added to the end of your network.
A simple narrative for our case is the following: The model learns the general mechanics of the English language with the Wikipedia corpus. We specialize in the model with the available transcripts both annotated and not annotated and in the end, we are able to classify this model by chopping the sequence component final layer with a regular Softmax based classifier.
LSTM & AWD Regularization Technique
At the core of UMLFit implementation is a bidirectional LSTM’s and a technique called ASGD WD ( Average Stochastic Gradient Descent Weight Dropped).
LSTM ( Long Short Term Memory) networks are the basic block of state of the art deep learning approaches to solve Transfer Learning in NLP sequence 2 sequence prediction problems. A sequence prediction problem consists of predicting the next word given the previous text:
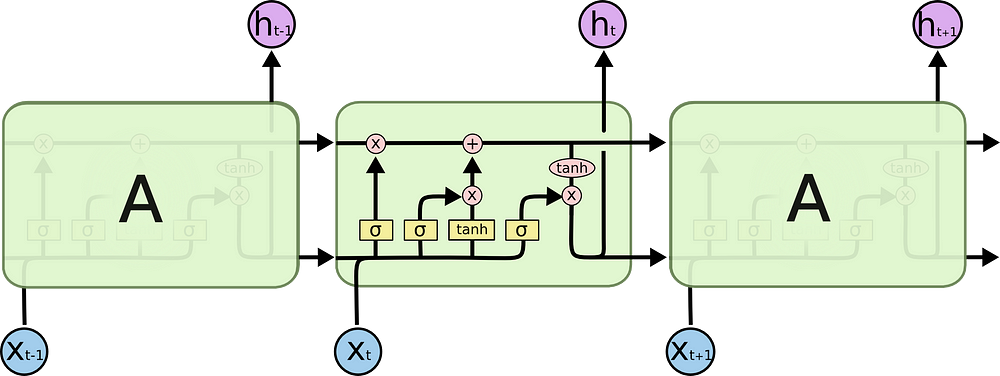
Copied from [6]
LSTM’s are ideal for language modeling and sequence prediction(increasingly being used in Time Series Forecasting as well ) because they maintain a memory of previous input elements. Each X element in our particular situation would be a token that would generate an output (sequence) and would be sent to the next block so it’s considered during the ht output calculation. Optimal weights will be backpropagated through the network-driven by the appropriate loss function.
One component of this regularization technique (WD) involves introducing dropouts on the weights of the hidden<->hidden states connections, which is quite unique compared with the drop out techniques.
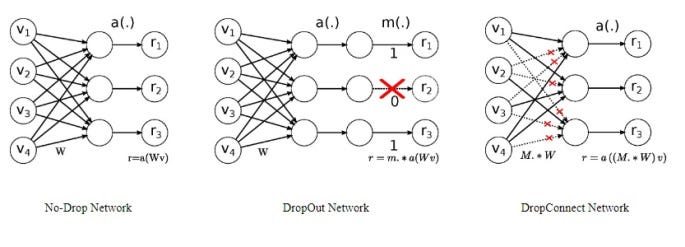
Copied from [7]
Another component of the regularization is the Average Stochastic Gradient Descent, that basically instead of just including the current step it also takes into consideration the previous step and returns an average[7]. More details about the implementation can be found here.
A more detailed ULMFit Diagram can be seen below where the LSTM’s components are described with the different steps of the implementation of the algorithm:
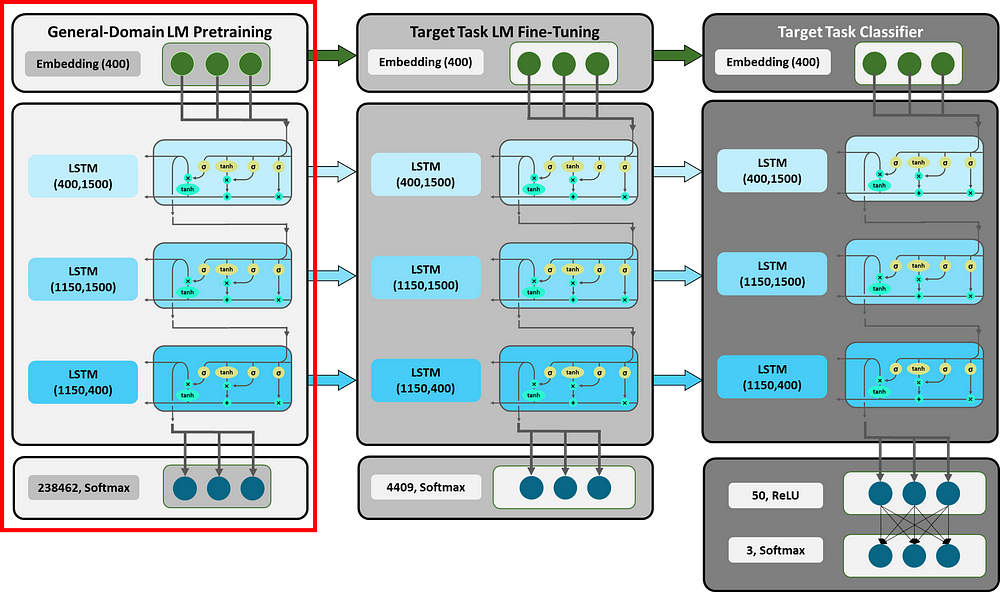
Copied from [5]
General-Domain LM (Language Model) Pretraining
This is the initial phase of the algorithm where a Language model is pre-trained in powerful machines with a public corpus of data-set. The language model problem is very simple: given a phrase the set of probabilities of the next word (probably one of the most oblivious use of Deep Learning in our daily lives):
We will use for this problem, in particular, the available FastAI implementation of ULMFit to elucidate the process in practical terms:
In order to choose the ULMFit implementation in fastai, you will have to specify the language model AWD_LSTM as mentioned before.
language_model_learner(data_lm, AWD_LSTM, drop_mult=0.5)
The code above does a lot in the good style of using the libraries FastAI and sklearn is being used to produce a train and validation set and fastai is being used to instantiate and UMLFit language model learner.
Target task LM Fine-Tuning
On the code presented on LM model section, we basically instantiate a pre-trained ULMFit language model with the right configuration of the algorithm ( there are other options for language models TransformersXL + QNNs ):
from fastai import language_model_learner from fastai import TextLMDataBunch from sklearn.model_selection import train_test_split # split data into training and validation set df_trn, df_val = train_test_split(final_dataset, stratify = df['label'], test_size = 0.3, random_state = 12) data_lm = TextLMDataBunch.from_df(train_df = df_trn, valid_df = df_val, path = "") learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.5)
The (pseudo)/code above basically retrieves our training and validation datasets stratified and creates a language_model_learner based on our own model. The important detail of the language model is that it doesn’t need annotated data ( perfect of our situation with limited annotated data but a bigger corpus of non annotated transcripts). Basically, we are creating a language model for our own specialized domain on top of the huge general Wikipedia kind of language model.
language_model_learner.unfreeze() language_model_learner.fit_one_cycle(1, 1e-2)
The code above basically unfreezes the pre-trained language model and executes one cycle of training on top of the new data with the specified learning rate.
Part of the process of ULMFit is applying discriminative learning rates through the different cycles of learning :
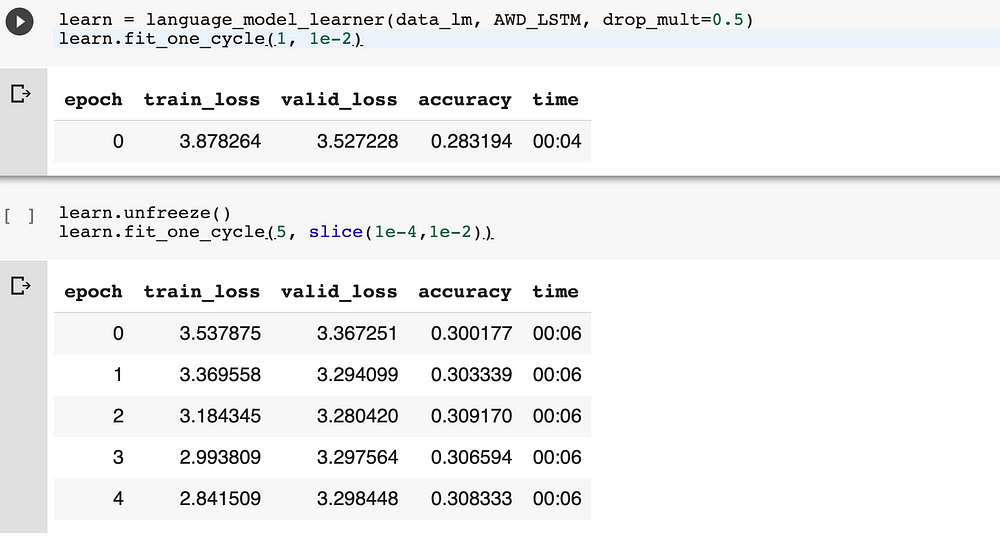
For a neural language model, the accuracy of around 30% is considered acceptable given the size of the corpus and possibilities [1].
After this point we are able to generate text from our very specific language model:

Excerpt from text generated from our language model.
At this point, we have a reasonable text generator for our specific context. The ultimate value of UMLFit is on the ability to transform a language model in a relatively powerful text classifier.
learn.save('ft')
learn.save_encoder('ft_enc')
The code above saves the model for further reuse.
Target Task Classifier
The last step of the ULMFit algorithm is to replace the last component of the language model with a classifier softmax “head” and train on top of it the specific labeled data on our project. It means the PTSD annotated transcripts.
classifier = text_classifier_learner(data_clas,
AWD_LSTM, drop_mult=0.5).to_fp16()
classifier.load_encoder('ft_enc')
classifier.fit_one_cycle(1, 1e-2)
#Unfreezing a train a bit more
classifier.unfreeze()
classifier.fit_one_cycle(3, slice(1e-4, 1e-2))
The same technique of discriminative learning rates was used above for the classifier with much better accuracy rates. Results on the classifier specifically were not the main goal for this article a subsequent article will delve into finetuning UMLFit comparison and addition of classifier specific metrics ranking and use of data augmentation techniques such us back-translation and different re-sampling techniques.
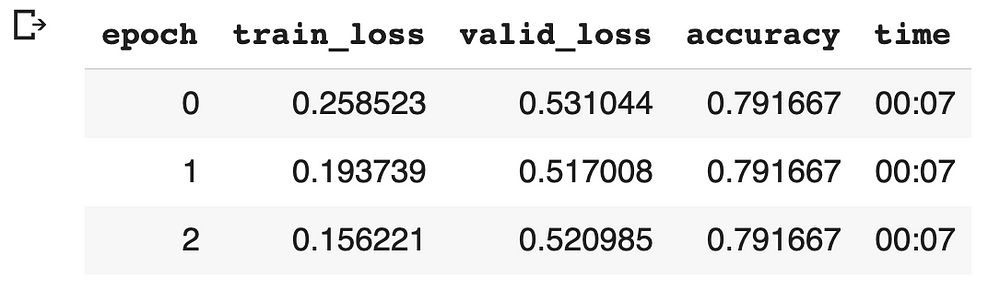
Initial Results of the UMLFit based classifier.



