
Named Entity Recognition with SpaCy to Identify Actors and Actions in News Articles
Identifying actors and actions in news articles about land conflicts and an attempt to resolve them in India using Named Entity Recognition with SpaCy.

Identifying actors and actions in news articles about land conflicts in India. The work has been part of an Omdena AI project with the World Resources Institute on identifiying land use conflicts and matching them with mediating government policies.
Suppose we have the following excerpt from a news article:

We want to identify within the article the following key elements (entities):
- Actor — who/what are the main actor(s) in the conflict referred to in this article?
- Action — what is the main action or event of a conflict in this article?
As human beings, this task is fairly simple — we would identify ‘tiger’, ‘farmer’ and ‘forest officials’ as the ‘actors’ and ‘attacked’ as the ‘action’. Things get a bit murky when it comes to defining ‘action’ in certain contexts (would you identify ‘tranquilize’ as the main action or not?). Overall humans would more or less agree on what the ‘actor’ and ‘action’ items are.
A model that can do this will be deemed a successful Named Entity Recognizer with SpaCy.

Pretty good, don’t you think? If you are curious how this works, read ahead!
The Problem: Resolving land conflicts in India
Typically, Named Entity Recognition (NER) happens in the context of identifying names, places, famous landmarks, year, etc. These entities come built-in with standard Named Entity Recognition packages like SpaCy, NLTK, AllenNLP.
The challenge for us was to create a custom entity recognizer as our entities were ‘non-standard’ and needed to be adapted to the AI challenge.
The World Resources Insitute (WRI) had approached Omdena to further its project on identifying land-related environmental conflicts in India, which affect more than 7 million people.

Land conflicts in India
The idea was to identify where the conflicts were happening, what groups of people it was affecting, the scale of the conflicts and to classify the kinds of conflicts and match it with the related governmental policy to resolve them faster.
Among these, identifying groups of people, scale, action, location, and date came under the scope of Named Entity Recognition using SpaCy.
In this article, we will deal with identifying actors, actions, and scales. Location and date are standard entities that can be obtained by plug-and-playing an off-the-shelf entity recognizer.
The data
The raw data initially was about 65000 news articles from Indian newspapers obtained from GDELT. In its own words, GDELT is ‘Creating a platform that monitors the world’s news media from nearly every corner of every country in print, broadcast, and web formats, in over 100 languages, every moment of every day and that stretches back to January 1, 1979, through present day.’ All the text was either originally in English or translated to English by GDELT.
The Solution: Coreference resolution
An important milestone identified before we started our labeling process was to identify the need for coreference resolution. Consider this fictional text,
‘Farmers were caught in a flood in Maharashtra. Kabir Narayan and Kamal Bashir were tending to their field when a dam burst and swept them away’.
Here, ‘Farmers’, ‘Kamal Narayan’, and ‘Kamal Bashir’ refer to the same entity. However, an entity recognizer will typically treat them as three separate entities. We wanted our entity recognizer to identify them all as ‘farmers’. This is where coreference resolution comes in. Coreference resolution is this essential pre-step in the entity recognition process that identifies entities ‘Kabir Narayan’ and ‘Kamal Bashir’ as referring to the same entity ‘farmer’ that occurs before. We won’t be able to go into any depths about how coreference resolution works. If you’re interested, here’s a useful blog that explains coreference resolution and also shows how to use spaCy’s coreference package, which is also what we used in our solution. Here’s also a blog by Zaheeda Tshankie, the task manager for the coreference resolution task — her take on what coreference resolution looked like in this particular case.
Some subtleties regarding entity labeling.
The next important step in this task was to manually label our entities. In order to train the model, Named Entity Recognition using SpaCy’s advice is to train ‘a few hundred’ samples of text. As it turned out in our case, we had manually identified about 1300 articles as either ‘positive’, i.e. as indeed referring to an environmental conflict or ‘negative’. In the beginning, we aimed to label 500 of these with our custom entities. However, we realized that this was not the easiest or the most suitable task. Here is some subtlety specific to entity recognition tasks — not all texts are suitable for all entity identification. For example, consider this text: ‘India is home to several hundred species of birds’. In this piece of text, it is difficult to identify the ‘action’. This is a descriptive text with no conflict that can be labeled as an ‘action’. For this reason, we decided to restrict our attention to the positive articles only. There were 147 of them.
There is a further subtlety regarding potentially nebulous entities such as ‘action’. From the beginning, the instructions were clear: we were to identify and label only the ‘main action’ of any news article. But, as we realized, this can be a fairly subjective task. For instance, consider the following text.
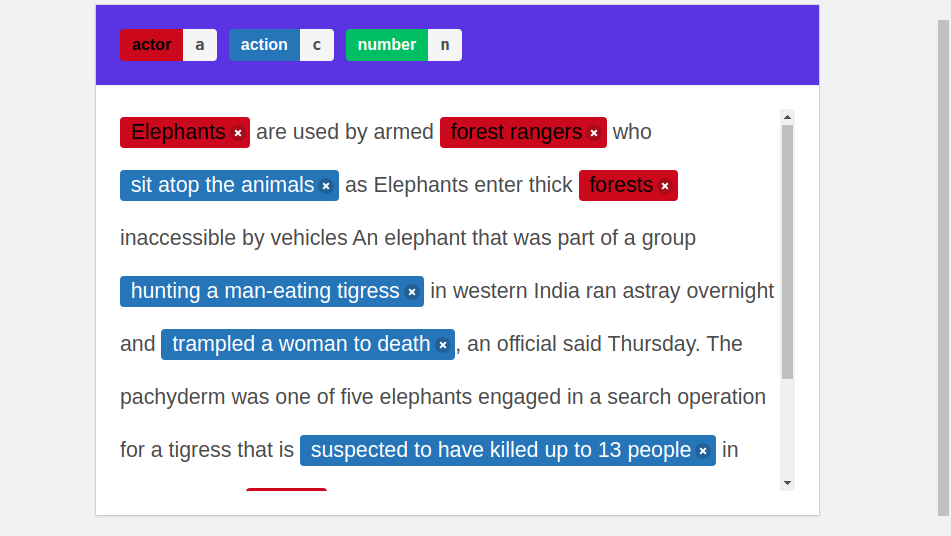
During the labeling, we encountered articles such as the one above. One example of labeling is as shown. This is not incorrect, however, I would have probably labeled this differently, marking only ‘killed’ as the ‘action’, ‘elephants’ and ‘tigress’ as ‘actors’. When we are working with several people during labeling, we have to account for the fact that people may misunderstand rules, through no fault of their own. Rather, the onus is on the rules and the more precise the rules are, the better the labeling process goes. This was a lesson well learned. However, sometimes even when the rules are precise, it is still possible to hit some ‘grey areas’ where it’s difficult to be completely objective and the subjectivity of the labeler comes into play. This is an inherent feature of ‘ambiguous’ labels like action and I am not sure if I have a solution to this. If you have any thoughts on this, please do leave them in the comments.
Pre-built entity recognizers
There are several libraries that have been pre-trained for Named Entity Recognition, such as SpaCy, AllenNLP, NLTK, Stanford core NLP. We decided to opt for spaCy because of two main reasons — speed and the fact that we can add neural coreference, a coreference resolution component to the pipeline for training.
If you would like a more detailed comparison of Named Entity Recognition, such as SpaCy libraries, here’s a blog on it.
Using Doccano
In order to make the labeling task as easy and efficient as possible, we decided to use Doccano’s annotating tool. Their description is as follows — ‘Doccano is an open-source text annotation tool for humans. It provides annotation features for text classification, sequence labeling, and sequence to sequence. So, you can create labeled data for sentiment analysis, named entity recognition, text summarization, and so on. Just create a project, upload data, and start annotation. You can build dataset in hours.’.
Here is what it looks like in practice.

Converting JSON1 to SpaCy format
Doccano provides entities in a JSON1 format and we needed to convert it to a tuple format that spaCy accepts. In the following, you can see the code. Credits to Tomasz Grzegozek.
import json
#Converting JSON1 files to Spacy tuples format
def convert_doccano_to_spacy(filepath):
with open(filepath, ‘rb’) as fp:
data = fp.readlines()
training_data = []
for record in data:
entities = []
read_record = json.loads(record)
text = read_record[‘text’]
entities_record = read_record[‘labels’]
for start, end, label in entities_record:
entities.append((start, end, label))
training_data.append((text, {“entities”: entities})
return training_data
Training the model
Here we used the following block of code, inspired by this blog.
TRAIN_DATA = train
def train_spacy(data,iterations):
TRAIN_DATA = data
nlp = spacy.blank(‘en’) # create blank Language class
# create the built-in pipeline components and add them to the pipeline
# nlp.create_pipe works for built-ins that are registered with spaCy
if ‘ner’ not in nlp.pipe_names:
ner = nlp.create_pipe(‘ner’)
nlp.add_pipe(ner, last=True)
#nlp.add_pipe(nlp.create_pipe(‘sentencizer’))
#Adding sentencizer as a prerequisite to coref
#neuralcoref.add_to_pipe(nlp) #Adding corefering in the pipeline
ner.add_label(ent[2])
# get names of other pipes to disable them during training
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != ‘ner’]
with nlp.disable_pipes(*other_pipes): # only train NER
optimizer = nlp.begin_training()
for itn in range(iterations):
print(“Starting iteration “ + str(itn))
random.shuffle(TRAIN_DATA)
losses = {}
for text, annotations in TRAIN_DATA:
nlp.update([text],
# batch of texts[annotations],
# batch of annotations
drop=0.2,
# dropout — make it harder to memorise data
sgd=optimizer,
# callable to update weights
losses=losses)
print(losses)
return nlp
custom_ner = train_spacy(TRAIN_DATA, 20)
# Save our trained Model
custom_ner.to_disk(‘Custom_NER_Model’)
Conclusion
The results of the training gave us some pretty good results. The model was especially good at picking up ‘actor’.

There were failures by the model, too. Here is an example.

In the example above, the model misses ‘massive protest’ as the important action and instead, identifies a long piece of text (which could be considered a secondary action) as the main action.
As mentioned before, defining ‘action’ is ambiguous even for humans, so it’s no wonder that the model got it wrong a few times. I do believe that with stricter rules for labeling, the model would have performed better.
You might also like
- Fight Misinformation And Detect Fake News using NLP
- 4 Steps of Using Latent Dirichlet Allocation for Topic Modeling in NLP
- Instant Monitoring System Combating Human Rights Abuses Through NLP


