
Topic Analysis to Identify and Classify Environmental Policies in LATAM
November 25, 2020

In an 8-week project, 50 technology changemakers from Omdena embarked on a mission to find needles in an online haystack. The project proved that using Natural Language Processing (NLP) can be very efficient to point to where these needles are hiding, especially when there are (legal) language barriers, and different interpretations between countries, regions, governmental institutes.
Introduction
The World Resource Institute (WRI) identified the problem and asked Omdena to help solve it. The project was hosted on Omdena´s platform to create a better understanding of the current situation regarding enabling policies through NLP techniques like topic analysis. Policies are one of the tools decision-makers can use to improve the environment, but often it is not known which policies and incentives are in place, and which department is responsible for the implementation.
Understanding the effect of the policies involves reading and topic analysis of thousands of pages of documentation (legislation) across multiple sectors. It is precisely in this area where Natural Language Processing (NLP) can help, and assist, in the processing of policy documents, highlighting the essential documents and parts of documents, and identifying which areas are under/over-represented. A process like this will also promote the knowledge sharing between stakeholders, and enable rapid identification of incentives, disincentives, perverse incentives, and misalignment between policies.
Problem Statement
This project aimed to identify economic incentives for forest and landscape restoration using an automated approach, helping (for a start) policymakers in Mexico, Peru, Chile, Guatemala, and El Salvador to make data-driven choices that positively shape their environment.
The project focused on three objectives:
- Identifying which policies relate to forest and landscape restoration using topic analysis
- Detecting the financial and economic incentives in the policies via topic analysis
- Creating visualization which clearly shows the relevance of policies to forest and landscape restoration
This was achieved through the following pipeline, demonstrated through Figure 1 below:
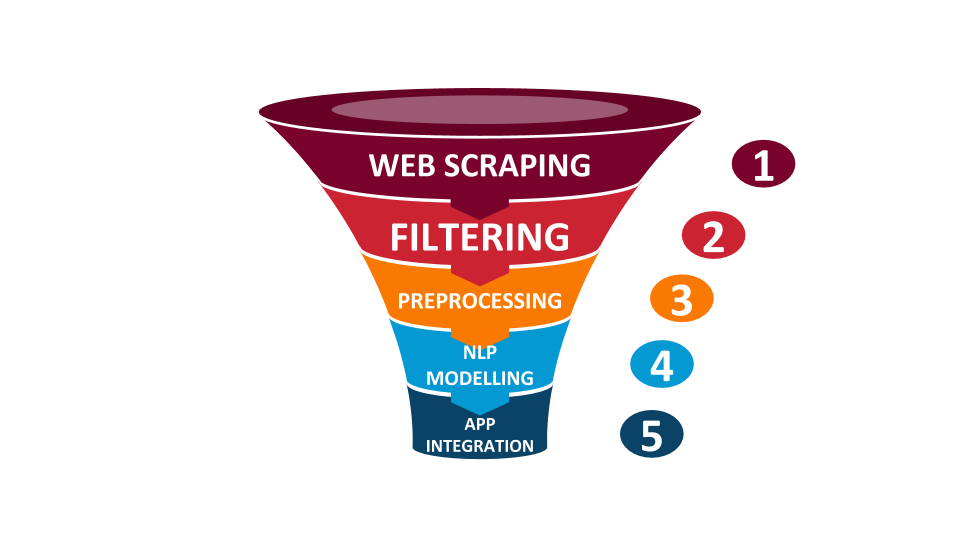
Figure 1: NLP Pipeline
The Natural Language Processing (NLP) Pipeline
The web scraping process consisted of two approaches: the scraping of official policy databases, and Google Scraping. This allowed the retrieval of virtually all official policy documents from the five listed countries roughly between 2016 and 2020. The scraping results were then filtered further by relevance to landscape restoration, and the final text metadata of each entry was then stored on PySQL. Thus, we were able to build a comprehensive database of policy documents for use further down the pipeline.
Text preprocessing converted the retrieved documents from a human-readable form to a computer-readable form. Namely, policy documents were converted from pdf to txt, with text contents tokenized, lemmatized, and further processed for use in the subsequent NLP models.
NLP modeling involved the use of Sentence-BERT (SBERT) and LDA topic analysis. SBERT was used to build a search engine that parses policy documents and highlights relevant text segments that match the given input search query. The LDA model was used for topic analysis, which will be the focus of this economic policies analysis article.
Finally, the web scraping results, SBERT search engine, and in the future, the LDA model outputs would be combined and the results presented into an interactive web app, allowing greater accessibility to the non-technical audience.
Applications for Natural Language Processing
All countries are creating policies, plans, or incentives, to manage land use and the environment and are part of the decision making process. Governments are responsible for controlling the effects of human activities on the environment, particularly those measures that are designed to prevent or reduce harmful effects of human activities on ecosystems, and do not have an unacceptable impact on humans. This policy-making can result in the creation of thousands of documents. The idea is to extract the economic incentives for forest and landscape restoration from the available (online) policy documents to get a better understanding of what kind of topics are addressed in these policies via topic analysis.
We developed a two-step approach to solving this problem: the first step selects the documents that are most closely related to reforestation in a general sense, and the second step points out the segments of those documents stating economic incentives. To mark which policies are relating to forest and landscape restoration we use a scoring technique (SBERT), to find the similarity between the search statement and sentences in a document, and a Topic Modelling technique (LDA), to pick out the parts in a document to create a better understanding of what kind of topics are addressed in these policies.
Analyzing the Policy Fragments with Sentence-BERT (SBERT)
To analyze all the available documents, and to identify which policies relate to Forest and Landscape Restoration, the documents are broken down into manageable parts and translated to one common language.
How can we compare different documents written in different languages and using specific words in each language?
The Multilingual Universal Sentence Encoder (MUSE) is one of the few algorithms specially designed to solve this problem. The model is simultaneously trained on a question answering task, (translation ranking task), and a natural language inference task (determining the logical relationship between two sentences). The translation task allows the model to map 16 languages (including Spanish and English) into a common space; this is a key feature that allowed us to apply it to our Spanish corpus.
The modules in this project are trained on the Spanish language, and due to the modular nature of the infrastructure this language can be easily switched back to the native language (English) in SBERT, subsequently, this project is working with a database of policy documents in Spanish but will work with any language base (Figure 2).
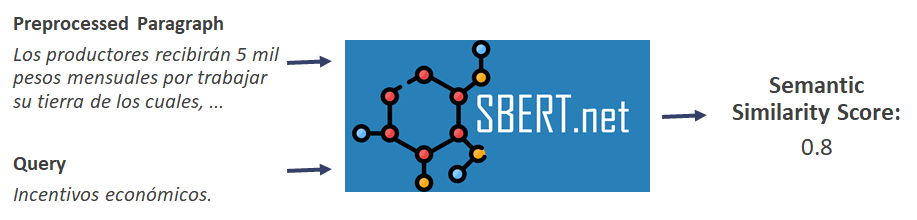
Figure 2: Visualisation of SBERT model, in Spanish.
Collecting all available online policies, by web scraping, in a country can result in a database of thousands of documents, and millions of text fragments, all contributing to the policy landscape in the country or region.
When we are faced with thousands of potentially important documents, where do we start from?
We have several options to solve this problem, for example, we can select a couple of documents and start from there. Of course, we can read the abstract if one such exists, but in real life, we may not be that lucky.
Another approach is using the bag-of-words algorithm; this is a simple technique that counts the frequency of the words in a text, allowing to deduce the content of the text from the highest-ranking words. (In this project we used CountVectorizer from sklearn to get the document-term matrix), which can then be displayed in a word cloud (using Wordcloud), for an easy, one-look summary of the document, like the one below.
This way we can get a quick answer to the question “What is the document about?”.
However, faced with thousands of documents, it is impractical to do word clouds for them individually. This is where topic modeling comes in handy. Topic Modeling is a technique to extract the hidden topics from large volumes of text. Latent Dirichlet Allocation (LDA) is a popular algorithm for topic modeling.
The LDA model is a topic classification model developed by Prof. Andrew Ng et al. of Stanford University’s NLP Laboratory. It is a generative model for text and other forms of discrete data that generalizes and improves upon previous models of the past, such as Bayes, unigram, and N-gram models.
Here’s how it works: Consider a corpus that comprises a collection of M documents, and each document formed by a selection of words (w1 w2, …, wi, …, wn). Additionally, each word belongs to one of the topics in the collection of topics (z1, z2, …, zi, …, zk). By estimating machine-learning weighted parameters, the per-document topic distributions, the per-document word distributions, and the topic distribution for a document, we can calculate the probabilities to which certain words are associated with certain topics, characterizing the topics and word distributions. Then, we can generate a distribution of words for each topic.
The LDA package outputs models with different values of the number of topics (k), each giving a measure of topic coherence value, a rough guide of how good a given topic model is.
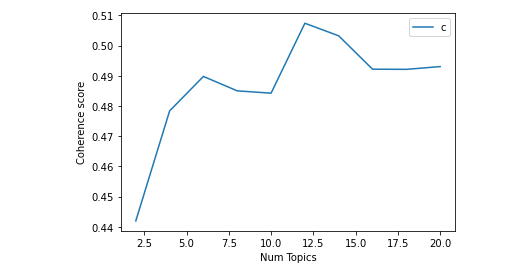
Figure 4: Coherence score vs. Number of topics
In this case, we picked up the one that gives the highest coherence value, without giving too many or too few topics, that would mean either not being granular enough, or difficult to interpret. ‘K’=12 marks the point of a rapid increase of topic coherence; a usual sign of meaningful and interpretable topics.
For each topic, we have a list of the highest-frequency words constructing the topic, and we can see some overarching themes appearing. Naming the topic is the next step, with the explicit caveat that setting the topic name is massively subjective, and the assistance of a subject matter expert is advisable. The knowledge of topics, and the keywords, is necessary because the topic should reflect the different aspects of the issues within the study or problem. For example, forest restoration can be seen as operating in the intersection of the following themes, defined by the LDA. Below is an example of a model with 12 topics, which happened to be the one with the most coherence, and the subjectively determined Topic Labels (Table 1).
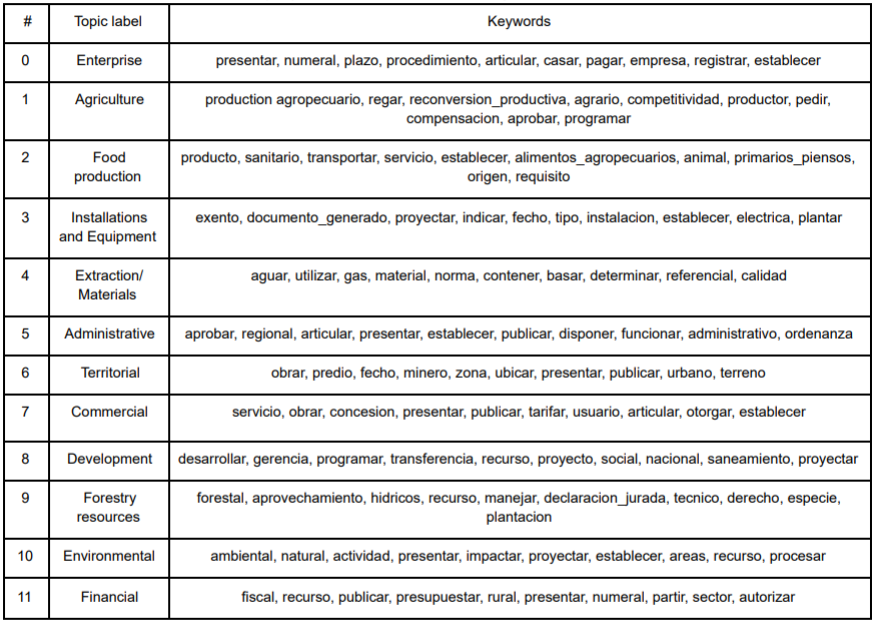
Table 1. Topic labels (12) and their respective keywords in the selected LDA model
We can see that one of the topics, “Forestry and Resources”, reflects closely the topics we are interested in, so the documents within it may be of particular relevance. The example document we saw before, “Sembrando Vida”, was assigned topic 8: “Development”, which is what it is expected from a document outlining the details of a broad incentive program. Some of the topics (e.g. Environmental, Agriculture) are related to the narrow topic of interest, whereas others (e.g. Food Production) are more on the periphery, and documents with this topic can be put aside for the time being. Thus topic modeling allows sifting the wheat from the chaff and zooming straight into more relevant documents.
The challenge of LDA is how to extract good quality topics that are clear, segregated, and meaningful. This depends heavily on the quality of text preprocessing and the strategy of finding the optimal number of topics, as well as the subject knowledge. Being familiar with the context and themes, as well as with different types of documents, is essential for this. Followed up with data visualizations, and further processing, like comparison, identifying conflicts between ministries, change of theme over time, zooming into the document, etc.
Results
The LDA process results in a table of topics defined by user-generated tags, and this table can be used to create a heat map (showing the frequency of the mentioning of a topic by country) and used for further evaluation of how, for example, the policies are differentiating between topics and regions; this process is illustrated in Figure 5.
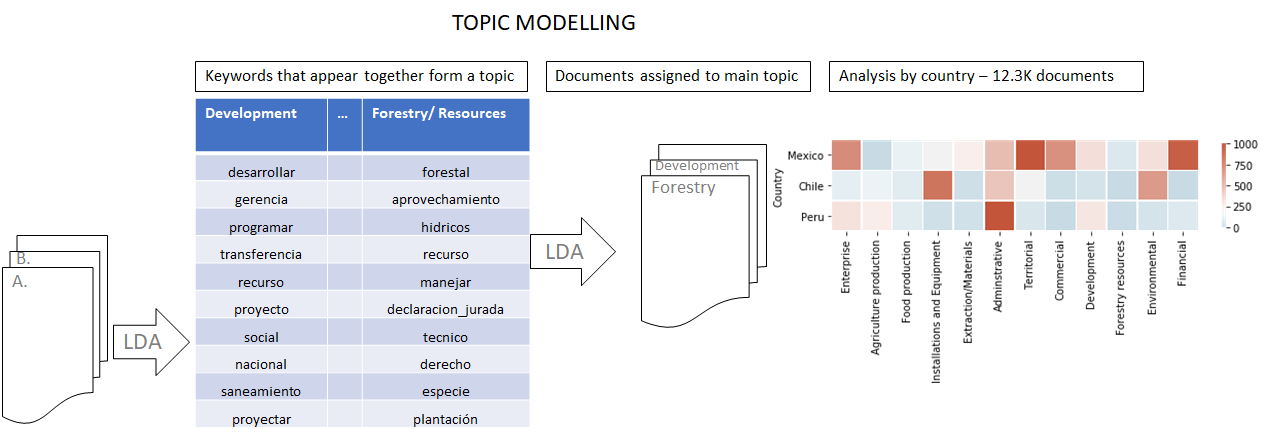
Figure 5: LDA model visualization
Heat maps
Based on this, the following visualization is generated (Figure 5). The horizontal axis contains the different topic labels in Table 1, while the vertical axis lists three countries: Mexico, Peru, and Chile. The heat map gives us insights into the different levels of categorical policy present in the three countries; for instance, a territorial-related policy is widely prevalent in Mexico, but not adopted widely in Chile or Peru.
This allows policymakers to observe the decisions made by other countries and how it compares to their local administration, enabling them to make better-informed choices in domestic policy that are supported by data-driven evidence.
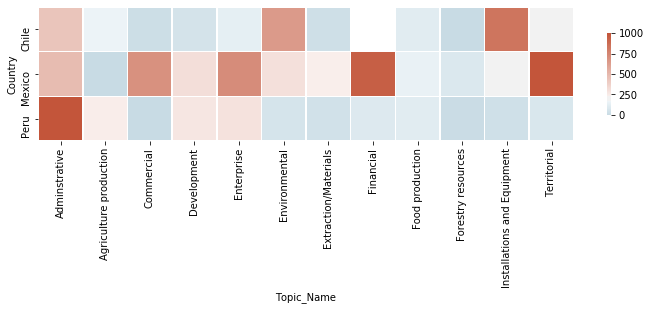
Figure 6: Heatmap displaying the frequency of appearance of LDA-defined policy topics by country
Next Steps
A valuable further development of topic analysis is to display policies (y) topics by the originator (ministries, etc.) to identify possible overlap and conflicts and to display change of topics in legislation and shifting focus over time. Going further into the documents, LDA can also be used to map out the topics in the different paragraphs, shifting the specific from generic information and identifying paragraphs of particular relevance. By zooming into specific documents, and then into specific document paragraphs, LDA is an efficient and flexible solution when faced with a huge volume of unclassified documents.
Conclusion: Topic Analysis for Policies
Finding needles in an online haystack is possible, especially with the help of the tools discussed, starting from a collection of web scraped documents, going through a data engineering process to clean up the found documents, and using the Latent Dirichlet Allocation (LDA) method to structure the documents, and fragments, by topics.
The data view by topic is a powerful way to see directly where what kind of policy is most dominant, and this information can be used to refine the search further or assist the policy-makers in defining the most efficient use of policies to create an environment where new policies are contributing to Forest and Landscape Restoration.
In the visualization space, possible enhancements include identifying overlaps and conflicts between government entities, highlighting the active policy areas, and displaying financial incentive information and projections.
In summary, the use of LDA is a promising way to navigate through complex environmental legislation systems and to retrieve relevant information from a vast compilation of legal text, from different sources, in multiple languages, and in quality.
This aricle is written by Gijs van den Dool, Galina Naydenova, and Ann Chia.
You might also like



