
5 Types of Classification Algorithms in Machine Learning + Real-World Projects
We'll take a look at some of the best classification algorithms in machine learning: Logistic Regression, Decision Tree, Naive Bayes,...

Which classification algorithms should you choose? It really depends on the type of problem you are trying to solve. In this article, we’ll take a look at the 5 types of classification algorithms in machine learning.
Classification algorithms are a fundamental part of machine learning, used to categorize data into different classes or groups. We’ll explore some of the most popular and effective classification algorithms, including Logistic Regression and Naive Bayes, and discuss their strengths and weaknesses.
Introduction
Imagine opening your cupboard to find all your stuff mixed up, making it difficult and time-consuming to take what you need. You might wish it was in a group together so it would save you time and effort. That’s what classification algorithms in machine learning do!
Classification is one of the critical aspects of supervised learning. Supervised learning classification in machine learning has uses in face detection, document classification, handwriting recognition, speech recognition, etc. In this article, we will look at various classification algorithms in machine learning and some of their applications in the real world.
What is a classification algorithm?
When we talk of supervised machine learning algorithms, classification, and regression algorithms are the two most broadly classified ones. The main difference between the two is that classification algorithms predict categorical values, while regression algorithms predict output for continuous values.
The use of classification algorithms in supervised learning is to identify the category of new observations based on training data. A classification algorithm learns from a given dataset and then classifies new observations into several classes or groups. We can call the classes labels or categories.
A good example of ML classification algorithms is – a machine learning classification algorithm that classifies into clear categories like Yes or No, or an email categorization as Spam or Not Spam, etc.
Why classification algorithms in machine learning is important?
Classification is core to machine learning as it teaches machines how to group data by any particular criteria like predetermined characteristics.
Classification in machine learning is a critical tool today with the rise in the application of big data for making decisions across industries. Classification helps data scientists and researchers to make better sense of data and find patterns. Using these data patterns offers greater insights into making more accurate data-driven decisions.
Common functionality of machine learning algorithms includes recognizing objects and separating them into categories. A good example is that it helps us segregate massive volumes of data into individually separate and distinct values like True/False, 0/1, or pre-defined output label classes.
You might also like
Top 5 machine learning algorithms for classification
Machine learning projects always need an in-depth understanding and classification of data. There are many ML algorithms for classification. Choosing the best classification model is more difficult, and many machine learning practitioners can try multiple classification models to find the best model for their data. However, two very simple methods get used to determine the best classification model for ML.
If your problem is linear, we recommend using logistic regression or a support vector machine (SVM).
How do you know if your problem is linear?
When you plot the problem on a graph, data traces a straight line, and any changes in an independent variable will always produce a corresponding change in the dependent variable.
If you have a non-linear problem, the best classification model to use for machine learning are K-Nearest Neighbor, Naive Bayes, or Decision Tree.
Let us look at the following ML algorithms for classification. Here we examine the machine learning classification algorithms when you should use a particular machine learning classifier algorithm, and we also look at machine learning algorithm examples for each.
Our chosen ML algorithms for classification are:
- Logistic Regression
- Naive Bayes
- K-Nearest Neighbors
- Decision Tree
- Support Vector Machines
1. Logistic Regression
What is logistic regression in ML?
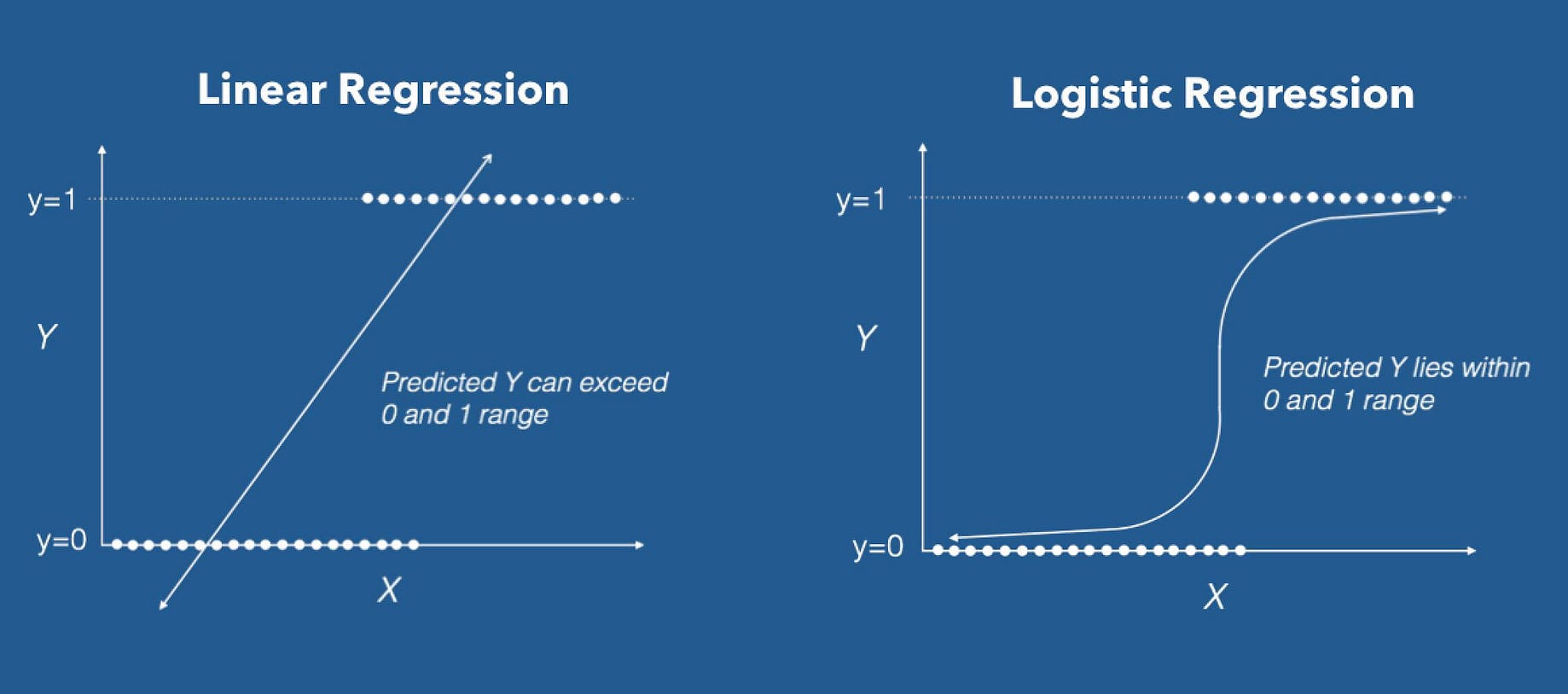
Logistic regression is a form of supervised learning classification algorithm that predicts the probability of a target variable. The target or dependent variable is dichotomous. It means there will be only two possible classes.
One can code data as either 1 (for success, or ‘Yes’) or 0 (which symbolizes Failure/No).

Linear Regression vs. Logistic Regression [Source]
When would you use the logistic regression example?
Logistic regression is best suited to predict the categorical dependent variable. You can use it when the prediction is categorical – for example, true or false, yes or no, or a 0 or 1. You can use a logistic regression algorithm to classify if an email is Spam or not.
For example with Real-world projects
A real-world example can be when a credit card company can know exactly how changes in transaction amount and credit score affect the probability of a given financial transaction being fraudulent. The transaction amount and credit score are the two predictor variables. The two potential outcomes are:
‘The transaction is fraudulent.’
‘The transaction is not fraudulent.’
On the other hand, Omdena built a risk predictor model for the mental impacts due to COVID-19. The model needs to identify and predict social media posts/tweets/videos by users with a high risk of mental health issues.
Supervised Learning – Classification model using Logistic regression was used for identifying two possible classes – whether the user is mentally impacted “Yes” or “No.” You can learn more about it in our blog link here.

Covid-19, Mental Health & Singapore
2. Naive Bayes
What is the Naive Bayes classification algorithm?
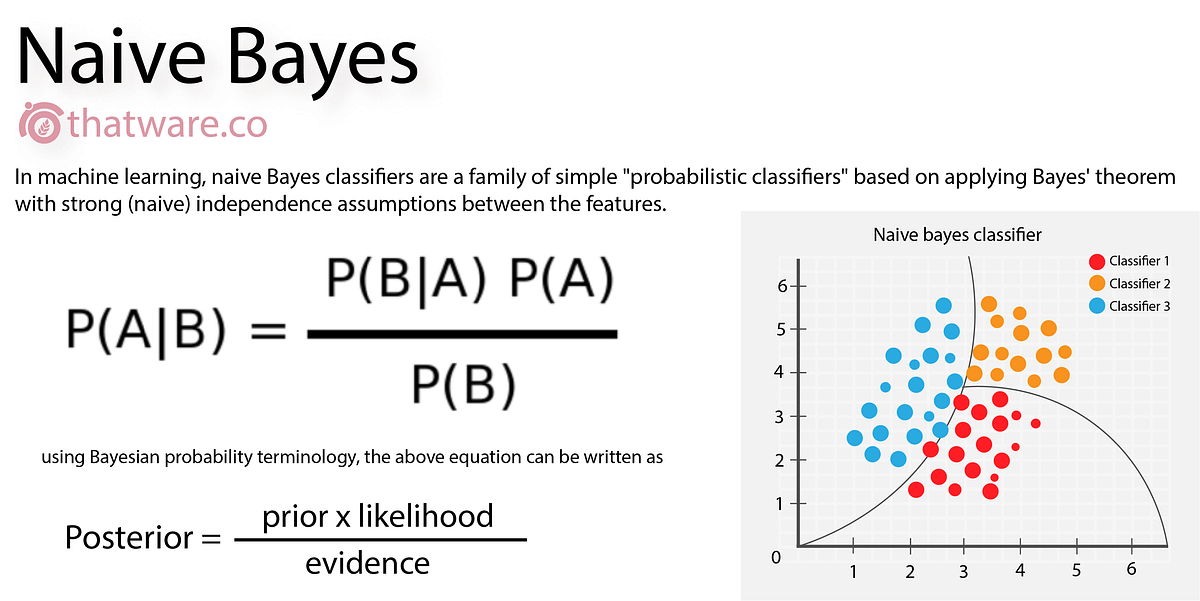
Naïve Bayes algorithm comes under the supervised learning algorithm category and is a simple classification algorithm that helps build fast machine learning models that can make quick predictions. The algorithm predicts based on the probability of an object and is also known as a probabilistic classifier.

Naive Bayes [Source]
What is the benefit of Naive Bayes?
The Naïve Bayes algorithm quickly predicts the class of the test data set. Moreover, it also performs accurately in a multi-class prediction scenario.
When we use an assumption of independence, a Naive Bayes classifier performs better than other models like logistic regression. It works with lesser training data too.
Why is Naive Bayes good for text classification?
Let us look at the following examples where text is important in the contents. Automated email filtering classifies the emails when working with emails that may contain a mix of spam and non-spam emails.
Similarly, sentiment analysis also uses text. For example, you might have heard about Twitter sentiment analysis that gauges consumer sentiment in case of a product launch or any recent event.
Naive Bayes classifier algorithm gives the best type of results as desired compared to other algorithms like classification algorithms like Logistic Regression, Tree-Based Algorithms, Support Vector Machines. Hence it is preferred in applications like spam filters and sentiment analysis that involves text. These applications are multi-class classification problems that may have a possibility of two or more outcomes for an event.
For example with Real-world projects
Common applications of Naive Bayes algorithm are in Spam filtering. Gmail from Google uses Naive Bayes algorithm for filtering spam emails. Sentiment analysis is another area where Naive Bayes can calculate the probability of emotions expressed in the text being positive or negative. Leading web portals may understand the reaction of customers to their new products based on sentiment analysis.
3. K-Nearest Neighbors
What is the K-Nearest Neighbor algorithm in ML?
The K-Nearest Neighbors (KNN) algorithm is a data classification method. It estimates the possibility that a data point will become a member of any of the groups based on what group the data points nearest to it belong to.

K-Nearest Neighbors [Source]
How does the K-Nearest Neighbors algorithm work?
In simple words, KNN classifies a data point by looking at the nearest annotated data point. (Known as the nearest neighbor.) If you are trying to determine if a data point is in group A or B, the algorithm looks at the data points near it. If a majority of the data points belong to Group A, then the data point in question is in group A and vice versa.
For example with Real-world projects
Finding The Ratio of Breast Cancer: In healthcare, the KNN algorithm is in use as a classifier to predict breast cancer based on the previous history of age, locality, and other conditions. Besides that, recommendation engines of portals like Netflix, Amazon, YouTube, etc. use them.
4. Decision Tree
What is a decision tree in classification?
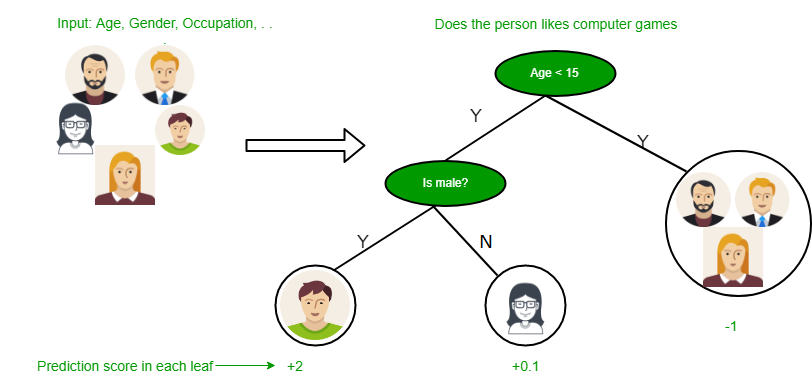
A decision tree is a Supervised learning technique. It can work in both classification and Regression problems but has a preference for solving classification problems. In a tree-structured classifier, the internal nodes represent the features of a dataset, branches represent the decision rules, and each leaf node represents the outcome.

Decision Tree [Source]
Why is a decision tree best for classification?
Decision trees are popular for classification as they can be used for both regression and classification, they are easy to interpret and don’t require feature scaling. Besides that, data cleaning requirements are less than other algorithms. It also excludes unimportant features.
For example with Real-world projects
Omdena used ML models for stress recognition to help us understand how stress works physically and mentally. This project used a decision tree algorithm and plotted its structure to identify key variables.
You can learn more about the project at the link here.

[Source]
5. Support Vector Machines
What are support vector machines (SVM) in ML?
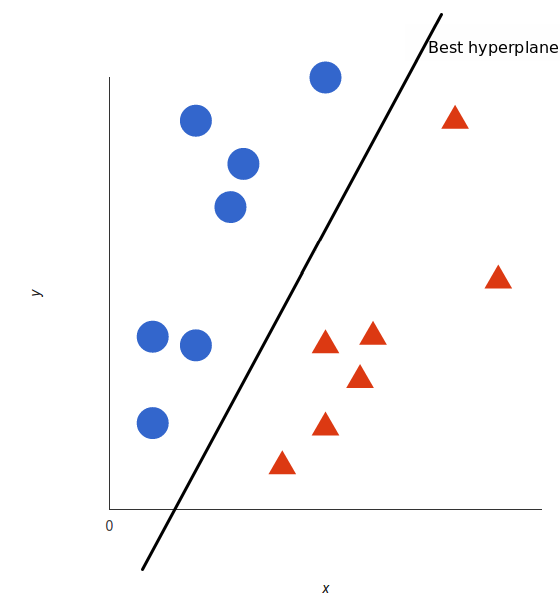
“Support Vector Machine” (SVM) is a supervised ML algorithm commonly used for classification and regression challenges. However, the preference is for use in classification problems. In an SVM algorithm (if N is a number of features), we plot each data item as a point in the N-dimensional space, with each feature being the value of a particular co-ordinate. We then perform classification by finding the hyper-plane that differentiates the two classes.

Support Vector Machines [Source]
What are the types of SVM?
There are primarily two types of Support Vector Machine (SVM): Linear SVM and Non-Linear SVM.
Linear SVM
We can use Linear SVM when the data is perfectly linearly separable. Perfectly linearly separable simply means that the data points can get classified into two classes by using a single straight line (if 2D).
Non-Linear SVM
When the data is not linearly separable, we can use Non-Linear SVM. In this case, the data points cannot get separated into two classes by using a straight line (if 2D). Using advanced techniques like kernel tricks helps to classify them. We do not find linearly separable data points in most real-world applications.
For example with Real-world projects
Common applications of SVM are applications like:
- Face detection: Face detection systems predict the identity of a given face. The use of a Linear Support Vector Machine (SVM) classifier model and the FaceNet model predicts a given face’s identity. Here SVM classifies parts of the image as a face and non-face and creates a square boundary around the face.
- Classification of images: SVMs provide better search accuracy during image classification.
- Bioinformatics: It includes protein classification and cancer classification. We use SVM to identify genes, patients based on genes, and other biological problems.
Conclusion
Classification algorithms perform a common task of recognizing objects and demonstrate the ability to separate them into categories successfully. ML classification uses algorithms to perform analytical tasks that would take humans a massive time to perform. That’s why classification algorithms in machine learning are getting immensely popular in the data science field.
Interested in real-world tutorials? Check out our exciting articles:
- How to Deploy Machine Learning Models Using Amazon SageMaker
- How to Deploy a Real-Time Computer Vision Model in Production
- How to Deploying an AutoML Model Using Streamlit [Step by Step]
- How to Build a Chatbot for Refugees Towards Using Rasa
- How to Use Autoencoders for Image Denoising [Quick Tutorial]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}