Continuous Training (CT) is the process of automatically retraining and serving machine learning models in production. Machine Learning models are built on the assumption that the data the model was trained on will be identical to the data used when making predictions. But that is not the case and data regularly drifts from what is expected. That is why Continuous Training is vital in any AI-driven organization.
This term was introduced by Google in their document,MLOps: Continuous delivery and automation pipelines in machine learning where CT is mentioned as the requirement for going from MLOps Level 0 (Manual Process) to MLOps level 1(ML Pipeline Automation) wherein level 1 MLOps the goal is to perform continuous training of the models by automating the ML pipeline.
The image below showcases an automated ML pipeline for Continuous Training:
Before going any further into Continuous Training of Machine Learning Models I would like to highlight a glaring issue I notice with most courses related to Machine Learning projects in that they forget about the cyclic nature of the ML Model lifecycle, assuming that once a model is deployed everything is all done and the project is a success. ML projects actually begin once the model has been deployed which is known as the post-deployment part.
Post Deployment of Machine Learning Models
When a model is in the post-deployment phase, it is now supposed to generate business value for the company by making predictions. In this part, either two things can happen:
1. The model works perfectly and stakeholders are happy with the business value derived from it (which rarely happens).
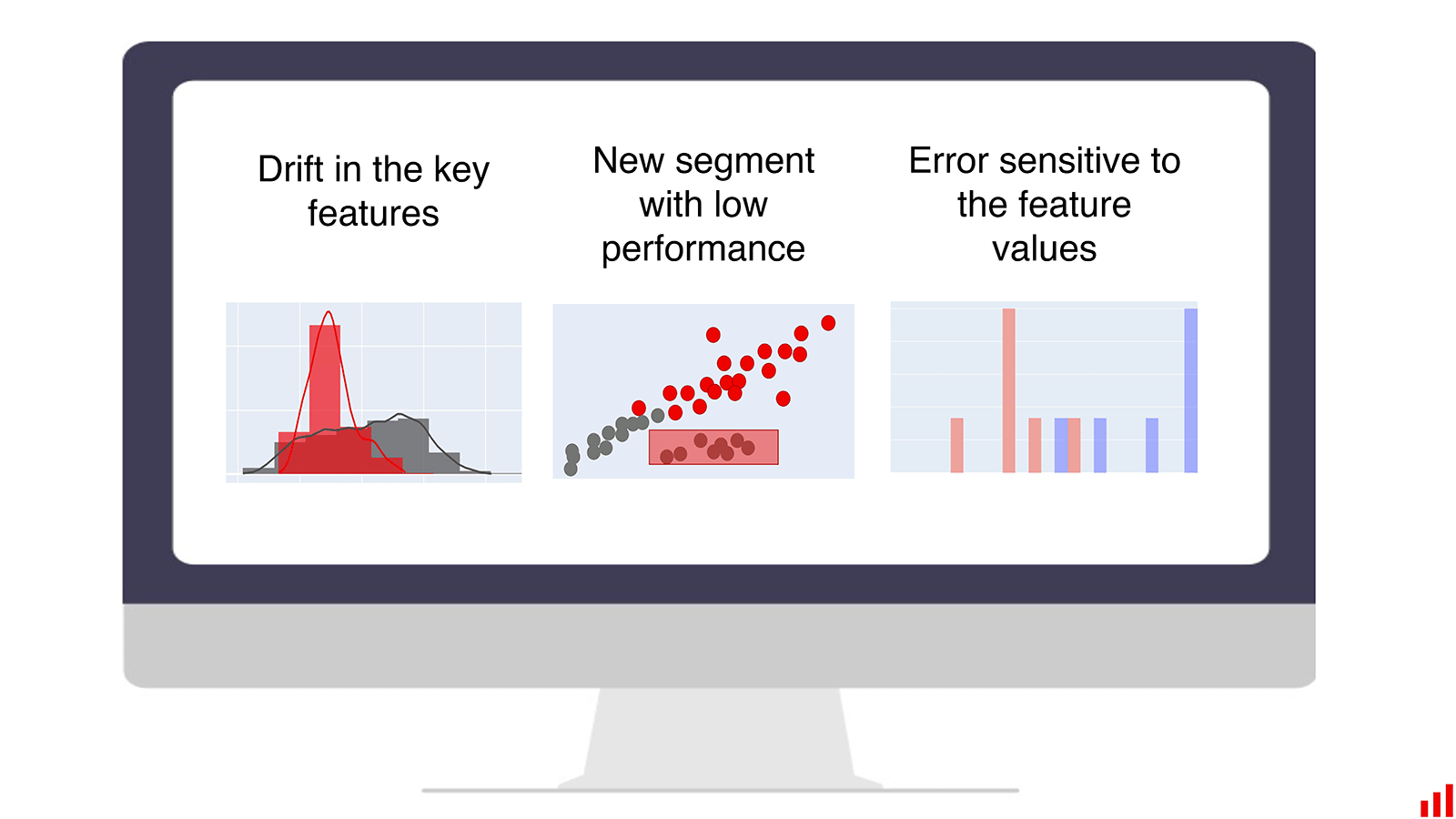
2. Issues regarding the model such as poor predictions on certain groups, inability to handle unseen data, etc. arise.
Looking at issues related to the data being fed to a model for predictions, there are a couple of different inherent issues that could arise such as the following:
1. Feature drift
2. Concept drift/Model drift(not covered in this article)
Model Monitoring
In order to evaluate if there is any type of drift, there needs to be a tool to monitor the models in production and how the data changes over time. Without this requirement it’s impossible to know in a real-time manner if there are any issues with a model, instead, you would have to query historical data and manually check it yourself which is a slow process and will easily result in drifts to go unnoticed for extended periods of time thus costing the business heavily.
Feature Drift is a change in the distribution over time, where a significant enough change in the input distribution compared to the reference distribution of the features is called feature drift.
In essence, there are two different choices that can be made here:
1. Retrain the model on the latest data (easier to do but could only be a bandaid for bigger issues within the data or model used)
2. Not retrain the model and reiterate through the Machine Learning Model Lifecycle (much more difficult to do due to the R&D nature of the solution which would be too slow of a reaction to solve the issue at hand)
Retraining a Machine Learning Model is not as simple as just getting some new data and training a model on it. There are nuances to the process that needs to be thought out carefully.
One thing to note about retraining is that it requires you have ground truth labels in the first place to train the model on. For use cases such as fraud detection, there is significant latency in getting back new ground truth labels in order to train the model. This latency is referred to as the blocker in the speed at which you retrain the model as you can’t retrain a model that gets new ground truth labels after a month in two weeks.
When to Retrain?
Periodic Retraining
A naive approach to retraining the model would be to just retrain it after a certain number of months or days. When starting out this is the easiest solution to start with and should be the recommended approach initially.
Data-Driven Retraining
A better approach would be to retrain once feature drift is actually detected using some sort of event-based architecture that would trigger the retraining pipeline to run once the model monitoring service detects feature drift. But this approach comes with the added complexity necessary from the event-based architecture as well as the integration with the model monitoring solution.
What Data to Retrain on?
Fixed Window Size
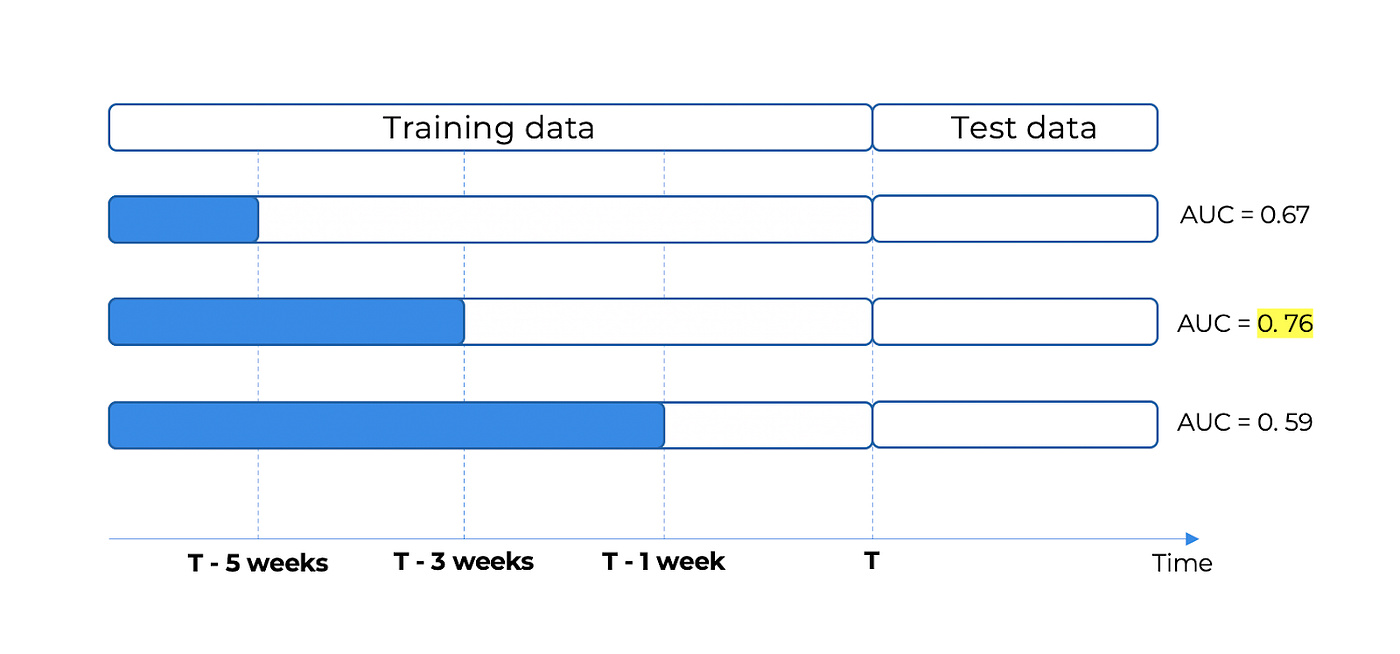
The easiest way to start when it comes to deciding what data we should retrain on would be to pick a fixed time interval. For example, the image below showcases a time interval from March 2021 to October 2021. Let’s say that our Machine Learning model was triggered in October 2021, we could just retrain the model on the past X months’ worth of data. Where X is 6 in this case.
Dynamic Window Size
A better solution to determining what data to retrain the model on is to treat the window size of the data to use to train the model as its own hyperparameter and pick the model from the respective time frame that is able to maximize or minimize the desired model metric.
Retraining a Machine Learning Model can be classified as a pipeline/workflow that can be automated using tools such as Kubeflow, Apache Airflow, Metaflow, etc.
Continuous Training Pipeline
The final version of a Continuous Training Pipeline should be like the image below.
Walkthrough of the entire process:
1. The Model Monitoring Service monitors the features that are used for a particular model in real-time.
2. The Model Monitoring Service notices a drift in the features of a model and then triggers an alert to be sent.
3. The alert triggers the retraining pipeline which will then extract the data from a Feature Store.
4. The Feature Store stores all the features used in an organization in a versioned and easy manner to allow for easy access by Data Scientists or pipelines.
5. With the data extracted the pipeline will then trigger the training of a new model called the contender model
6. The model is then evaluated
7. Once the model is evaluated it is then saved to a Model Registry which versions and keeps track of all the models within an organization.
8. The contender model is then run through the CI/CD pipeline and deployed to the model prediction endpoint
9. The model prediction endpoint is used to make predictions to the users through an API

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}